大数据去重算法:从 Bitmap 到 HyperLogLog
去重分析(COUNT DISTINCT)在企业日常分析中使用频率极高——UV 统计、独立设备数、活跃用户数——本质都是去重。如何在大数据场景下快速完成去重,一直是 OLAP 引擎的核心挑战之一。
一、为什么去重是大数据的痛点
先看一个典型场景:一张商品访问表有 item 和 user_id 两列,需要按商品求 UV(SELECT item, COUNT(DISTINCT user_id) FROM visits GROUP BY item)。
数据分布在多个节点上。如果是简单的 COUNT,每个节点各自统计再相加就行,shuffle 量极小。但 COUNT DISTINCT 不同——必须把同一个 item 的所有 user_id 收集到一个节点上才能去重,shuffle 量等于原始数据量。当 user_id 达到亿级,这个 shuffle 就是性能杀手。

核心问题:我们最终只需要一个"不重复元素个数",能否用一种更紧凑的数据结构替代原始值的集合,在大幅减少 shuffle 数据量的同时,依然能正确(或近似正确)地计算基数?
两类算法给出了解答:
| 类型 | 代表算法 | 精确度 | 空间复杂度 | 适用场景 |
|---|---|---|---|---|
| 精确去重 | Bitmap / Roaring Bitmap | 100% 精确 | 与基数成正比 | 财务对账、精确 UV |
| 近似去重 | HyperLogLog | 误差 ~0.8%-6.5% | 几乎常数(KB 级) | 大盘 UV、趋势分析 |
下面分别拆解。
二、精确去重:Bitmap 与 Roaring Bitmap
2.1 Bitmap 的基本原理

Bitmap(位图)用一个 bit 数组来表示一个集合——每个元素对应数组中的一位,1 表示存在,0 表示不存在。集合 {2, 3, 5, 8} 对应的 Bitmap 是 [0,0,1,1,0,1,0,0,1],数组中 1 的个数就是基数。
核心优势:用 1 bit 表示一个元素。一个 Integer(32 位)的元素,原始存储需要 4 Bytes,Bitmap 只需要 1 bit——节省 32 倍。
核心问题:一个能存放所有 Integer 值的 Bitmap 需要 2^32 位 = 512 MB,无论集合中有 1 个元素还是 40 亿个元素,占用空间都是 512 MB。对于冷门商品(只有几个访问),这个开销完全不可接受。
// 基础 Bitmap 的概念实现
public class SimpleBitmap {
private long[] words; // 每个 long 存储 64 个 bit
public SimpleBitmap(int maxValue) {
this.words = new long[(maxValue >> 6) + 1];
}
public void add(int value) {
words[value >> 6] |= (1L << (value & 63));
}
public boolean contains(int value) {
return (words[value >> 6] & (1L << (value & 63))) != 0;
}
public long cardinality() {
long count = 0;
for (long word : words) {
count += Long.bitCount(word);
}
return count;
}
}
2.2 Roaring Bitmap:精巧的自适应结构

Roaring Bitmap 是一种设计精巧的压缩 Bitmap,完美解决了上述空间问题。它的核心思想是分层 + 自适应容器:
- 将 32 位 Integer 拆分为高 16 位(作为 key)和低 16 位(存入 Container)
- 根据数据密度,自动选择最优的 Container 类型
三种 Container:

Array Container(稀疏数据):
- 内部是有序的 short 数组,初始容量 4,最大容量 4096
- 超过 4096 个元素时自动转换为 Bitmap Container
- 存储 N 个元素占用 2N Bytes

Bitmap Container(密集数据):
- 固定 1024 个 long 值,占用 8 KB
- 无论存 1 个还是 65536 个元素,空间恒定
- 当 Array Container 元素超过 4096 时,两者占用相同(8 KB),此后 Bitmap Container 更优

Run Container(连续数据):
- 使用游程编码(RLE)压缩连续值
- {11, 12, 13, 14, 15, 21, 22} 编码为 (11,4), (21,1)
- 最好情况:65536 个连续元素只需 4 Bytes
- 最坏情况:全部不连续时占 128 KB
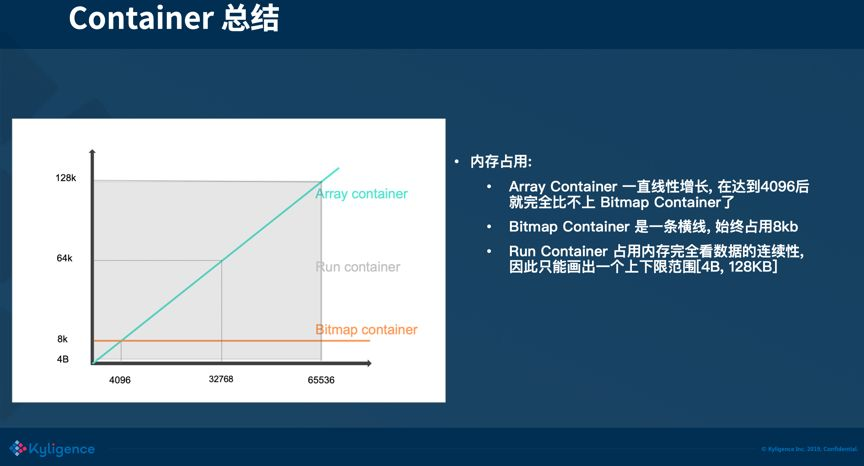
三种 Container 的空间占用对比:
| 元素个数 | Array Container | Bitmap Container | Run Container |
|---|---|---|---|
| 100 | 200 B | 8 KB | 取决于连续性 |
| 4,096 | 8 KB | 8 KB | 取决于连续性 |
| 10,000 | 20 KB | 8 KB | 取决于连续性 |
| 65,536 | 128 KB | 8 KB | 4 B ~ 128 KB |
交叉点在 4096:元素数 < 4096 时 Array 最优,> 4096 时 Bitmap 最优,连续数据用 Run 最优。Roaring Bitmap 自动完成容器类型的切换,使用方无需手动指定。
工程建议:在高基数场景(如用户 ID 去重),Array Container 的频繁 resize 会导致大量内存分配和复制。建议将
DEFAULT_MAX_SIZE从默认的 4096 调低到 1024 或 2048,减少 resize 开销。
2.3 非数值类型的处理:全局字典
Bitmap 要求元素是数值类型,但实际业务中去重列经常是字符串(如 device_id、session_id)。解决方案是构建全局字典——将字符串映射为整数 ID,再放入 Bitmap。
全局字典在高基数列(数亿级不重复值)时会成为性能瓶颈。常见的优化策略:
| 优化策略 | 原理 | 适用场景 |
|---|---|---|
| 字典复用 | 当一个列的值完全被另一列包含时,复用已有字典 | 维度表的外键列 |
| Segment 字典替代 | 当分析不跨时间分片时,用分片内字典替代全局字典 | 单日/单分片查询 |
| 多列族存储 | 将多个精确去重指标放到不同列族,减少读放大 | 多个 COUNT DISTINCT 指标并存 |
三、近似去重:HyperLogLog
3.1 为什么需要近似去重
Bitmap 是精确的,但空间占用与基数成正比。当基数达到数十亿时,即使是 Roaring Bitmap,单个实例也可能占用数十 MB。如果有上万个分组(比如按商品求 UV),总内存开销不可忽视。
HyperLogLog(HLL)提供了另一种思路:用极小的固定空间(KB 级),换取可接受的误差(通常 < 2%)。

HLL 的三个核心特性:
- 完整遍历所有元素一次(不采样、不多轮)
- 只能计算基数,不能判断某个元素是否存在
- 多个 HLL 实例可以合并(支持分布式聚合)
3.2 直觉理解:抛硬币实验

想象你在做一个实验:不停抛硬币,记录连续抛到正面的最长次数。如果最长记录是 3 次,你大概没做太多次实验;如果最长记录是 20 次,你可能做了上百万次。
这就是 HLL 的核心思想——通过观察到的极端值来估算总量。当然,一个人可能运气极好第一次就连抛 20 次正面,所以需要多人同时实验(分桶),用调和平均来降低方差。
3.3 算法实现
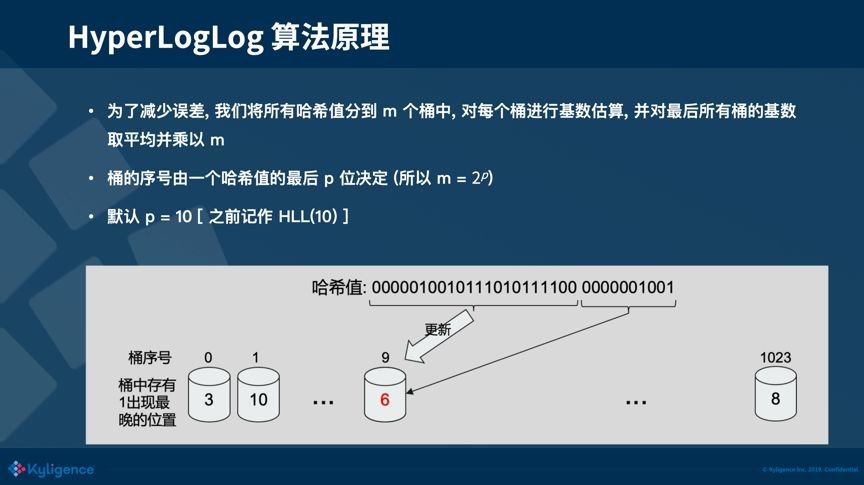
HLL 的完整流程:
- Hash:对每个元素求 Hash 值,得到一串二进制位
- 分桶:取 Hash 值的后 k 位确定桶号(精度参数,如 HLL(10) 有 2^10=1024 个桶)
- 记录:在剩余位中找到第一个 1 出现的位置,更新到对应桶中(取最大值)
- 估算:对所有桶的值取调和平均数,代入公式估算基数
# HyperLogLog 核心逻辑的简化实现
import hashlib
import math
class HyperLogLog:
def __init__(self, precision=14):
self.p = precision
self.m = 1 << precision # 桶数量: 2^p
self.registers = [0] * self.m # 每个桶记录"第一个1的最晚位置"
self.alpha = 0.7213 / (1 + 1.079 / self.m) # 修正常数
def add(self, value):
h = int(hashlib.md5(str(value).encode()).hexdigest(), 16)
bucket = h & (self.m - 1) # 后 p 位确定桶号
remaining = h >> self.p # 剩余位
# 找第一个 1 出现的位置
first_one = 1
while remaining and not (remaining & 1):
first_one += 1
remaining >>= 1
self.registers[bucket] = max(self.registers[bucket], first_one)
def cardinality(self):
# 调和平均数估算
harmonic_mean = sum(2 ** (-r) for r in self.registers)
estimate = self.alpha * self.m * self.m / harmonic_mean
return int(estimate)
def merge(self, other):
"""合并两个 HLL 实例(分布式聚合的关键)"""
for i in range(self.m):
self.registers[i] = max(self.registers[i], other.registers[i])

为什么用调和平均数而非算术平均数:调和平均数会偏向较小的值,能有效过滤极端值的影响(类似"你和马云的平均工资"问题)。
3.4 空间与精度

空间复杂度:O(m * log2(log2(N)))
- N 是基数(最大 2^64)
- log2(2^64) = 64,一个桶最多记录"第 64 位"
- log2(64) = 6,6 个 bit 就能存储 0-64 的值
- m 个桶 = m * 6 bit
| 精度 | 桶数 | 空间占用 | 标准误差 |
|---|---|---|---|
| HLL(10) | 1,024 | ~768 B | ~3.25% |
| HLL(12) | 4,096 | ~3 KB | ~1.63% |
| HLL(14) | 16,384 | ~12 KB | ~0.81% |
| HLL(16) | 65,536 | ~48 KB | ~0.41% |

关键特性:空间占用与基数 N 无关,只与精度参数 p 相关。无论去重 1 万个还是 10 亿个元素,HLL(14) 始终只占 12 KB。
注意:HLL 在低基数(< 1000)时误差会偏高。如果基数可能很低,建议使用精确去重或在 HLL 基础上做小基数修正(Linear Counting)。
四、Bitmap vs HyperLogLog:选型框架
4.1 核心对比
| 维度 | Bitmap(Roaring) | HyperLogLog |
|---|---|---|
| 精确度 | 100% 精确 | 误差 0.4%-6.5%(取决于精度) |
| 空间复杂度 | O(N),与基数成正比 | O(1),几乎常数(KB 级) |
| 时间复杂度 | O(N) | O(N) |
| 可合并性 | 支持(OR 操作) | 支持(取 max 操作) |
| 反向查询 | 支持(判断某元素是否存在) | 不支持 |
| 非数值类型 | 需要全局字典映射 | Hash 后直接使用 |
| 适合基数范围 | 千万级以内最优 | 任意(亿级以上优势明显) |
4.2 选型决策树
| 如果你的场景是... | 选择 | 理由 |
|---|---|---|
| 财务对账、精确 UV 报表 | Bitmap | 零误差是硬性要求 |
| 大盘 UV 趋势、实时监控 | HLL | 2% 的误差可接受,空间节省数百倍 |
| 基数 < 1000 万,需要精确 | Bitmap | Roaring Bitmap 空间可控 |
| 基数 > 1 亿,允许近似 | HLL | Bitmap 单实例可能占数十 MB |
| 需要判断"某用户是否访问过" | Bitmap | HLL 不支持成员查询 |
| 需要跨维度灵活聚合 | HLL | 合并操作极快(取 max),适合预聚合 |
| 内存预算极其有限 | HLL | 固定 KB 级开销 |
4.3 与其他去重/概率算法的关系
| 算法 | 用途 | 和去重的关系 |
|---|---|---|
| Bloom Filter | 判断元素"可能存在"或"一定不存在" | 不计算基数,只做成员判断 |
| Count-Min Sketch | 估算每个元素的出现频率 | 不去重,计频次 |
| Linear Counting | 低基数场景的基数估算 | HLL 的低基数修正方案 |
| Theta Sketch | 支持集合运算(交/并/差)的基数估算 | HLL 的超集,支持更复杂的集合操作 |
五、工程实践
5.1 在 OLAP 引擎中的应用
以 Apache Kylin 为例(同时支持精确和近似去重):
- 精确去重:编辑度量时选择 COUNT DISTINCT,Return Type 选 Precisely → 底层使用 Roaring Bitmap
- 近似去重:Return Type 选择 HLL 精度级别(如 HLL(14))→ 底层使用 HyperLogLog
其他主流引擎的支持情况:
| 引擎 | 精确去重 | 近似去重 |
|---|---|---|
| Apache Kylin | Roaring Bitmap | HyperLogLog |
| ClickHouse | uniqExact(Hash Set) |
uniq(HLL),uniqCombined(自适应) |
| Apache Doris | Bitmap 类型 | HLL 类型 |
| Elasticsearch | 精确聚合(高开销) | cardinality(HLL) |
| Redis | 无内置 | PFADD / PFCOUNT(HLL) |
5.2 Redis HyperLogLog 实战
Redis 内置了 HLL 支持,使用极其简单:
# 添加元素
PFADD page_uv:2026-04-07 user_001 user_002 user_003
PFADD page_uv:2026-04-07 user_001 user_004 # user_001 重复,不影响
# 查询基数
PFCOUNT page_uv:2026-04-07
# → (integer) 4
# 合并多天的 UV(去重后的 UV 总数)
PFMERGE page_uv:week page_uv:2026-04-01 page_uv:2026-04-02 ... page_uv:2026-04-07
PFCOUNT page_uv:week
Redis 的 HLL 实现使用 12 KB 固定空间(精度约 HLL(14),标准误差 0.81%),无论存入多少元素。
5.3 性能基准参考
以 1 亿个 UUID 去重为例(参考值,实际因环境而异):
| 方案 | 空间占用 | 构建时间 | 查询时间 | 误差 |
|---|---|---|---|---|
| Hash Set(精确) | ~6 GB | ~60s | O(1) | 0% |
| Roaring Bitmap + 字典 | ~120 MB | ~45s | O(1) | 0% |
| HLL(14) | 12 KB | ~30s | O(1) | ~0.81% |
空间差距:Hash Set 6 GB → Roaring Bitmap 120 MB(50x 压缩)→ HLL 12 KB(50万x 压缩)。
总结

回到最初的场景——按商品求 UV。使用 Bitmap 或 HLL 后,每个 item 对应的不再是原始 user_id 集合,而是一个 Bitmap 实例或 HLL 实例。Shuffle 的数据量从"所有 user_id 的原始值"降低到"一个压缩后的数据结构",性能提升可达数个数量级。
选型原则很简单:
- 必须精确 → Bitmap(Roaring Bitmap)
- 允许近似 + 基数大 → HyperLogLog
- 拿不准 → 先用 HLL 做大盘监控,精确场景再补 Bitmap
两者不是替代关系,而是互补关系。在同一个系统中,财务报表用 Bitmap 保精确,运营大盘用 HLL 省资源——这是最常见的生产实践。