当所有常规路径都被堵死:一次非侵入式 SQL 监控的工程突围
问题:一条不合作的执行链路
SQL 监控是后端工程中最基础的需求之一:参数化 SQL 绑定实际值、超长参数列表缩略打印、执行耗时统计与慢查询报警。如果你使用了成熟的 ORM 框架(MyBatis Interceptor、JOOQ Listener),这些都不是问题。
但如果你的技术栈不提供这些能力呢?
一个 SQL 请求的执行链路:DAO → ORM → DataSource → Connection → Driver → DB。要实现独立于 ORM 的通用监控,可以在 DataSource → Connection → Driver 三个环节切入:
| 切入点 | 方式 | 代表工具 |
|---|---|---|
| Driver 层 | JDBC URL 加 logger 参数 | MySQL profileSQL |
| Connection 层 | 代理驱动,修改 JDBC URL | P6Spy、log4jdbc |
| DataSource 层 | 包装 DataSource 对象 | P6DataSource |
三种方案都可以实现 SQL 监控。但在实际生产环境中,只有第三种是可行的。
约束条件
这套系统的基础设施有几个硬约束:数据库连接由 DBA 在平台配置,底层数据源是 ShardingSphere + HikariDataSource 的深度封装。
- Driver 层方案:需要在 JDBC URL 中加
logger=Slf4JLogger&profileSQL=true,而 URL 由 DBA 维护,修改流程长且和标准配置冲突。另外,不同数据库的 Driver 实现不统一(Oracle 就不支持 profileSQL)——排除 - Connection 层方案:同样需要修改 JDBC URL(
jdbc:p6spy:mysql://...),且比 Driver 层方案更容易配错——排除 - DataSource 层方案:不需要改 URL,只需在运行时包装 DataSource 对象——唯一可行
到这里似乎清晰了:用 P6DataSource 包装原始 DataSource 就行。但问题没这么简单——在这套框架中,DataSource 的创建被深度封装,业务代码根本拿不到 DataSource 实例。
框架提供的数据访问入口是一个 DataSourceConfig 接口:
public interface DataSourceConfig {
String bizName();
default NamedParameterJdbcTemplate read() {
return InternalDatasourceConfig.readForceAz(this, currentAz(), currentPaz(), "read");
}
default NamedParameterJdbcTemplate write() {
return InternalDatasourceConfig.writeForceAz(this, currentAz(), currentPaz(), "write");
}
}
业务方通过枚举继承该接口来定义数据源,调用时只能拿到 JdbcTemplate,DataSource 在框架内部创建和管理,不对外暴露。
约束升级了:我们不仅不能改 URL,连 DataSource 对象都摸不到。需要在不修改框架代码的前提下,拦截 DataSource 的创建过程。
核心突破:顺着继承链找到注入点
这是整篇文章最关键的部分——不是"怎么改字节码",而是**"改哪里"**。
定位 DataSource 的创建位置
第一步是找到 DataSource 到底在哪里被 new 出来的。框架代码虽然不能修改,但反编译后源码是可以阅读的。
追踪方法有两个:一是在 IDE 中对 HikariDataSource 的构造方法设断点,启动应用后查看调用栈;二是在依赖 jar 中全局搜索 new HikariDataSource。两种方法都能快速定位到同一个位置。
沿着调用链一路追踪:
DataSourceConfig.read()
→ InternalDatasourceConfig.readForceAz()
→ DataSourceFactory.create()
→ new ListenableDataSource<>(bizName, new HikariDataSource(config), ...)
DataSourceFactory.create() 的关键代码:
public static ListenableDataSource<Failover<Instance>> create(Instance i) {
return supplyWithRetry(
DATA_SOURCE_BUILD_RETRY,
DATA_SOURCE_BUILD_RETRY_DELAY,
() -> new ListenableDataSource<>(
bizName,
new HikariDataSource(config), // ← 真正的 DataSource 在这里创建
ds -> i.toString(), i),
DataSourceFactory::needRetry);
}
最直接的想法:把 new HikariDataSource(config) 改成 new P6DataSource(new HikariDataSource(config))。但这是框架的代码,没有修改权限。如果只盯着 DataSourceFactory,就会陷入死胡同。
继承链上的转折
转折点在于:看一下 ListenableDataSource 的继承关系。
ListenableDataSource
→ extends DelegatingDataSource (Spring JDBC)
→ implements DataSource
DelegatingDataSource 是 Spring JDBC 提供的标准委托类,它的构造方法和 setter:
public class DelegatingDataSource implements DataSource {
public DelegatingDataSource(DataSource targetDataSource) {
this.setTargetDataSource(targetDataSource);
}
public void setTargetDataSource(@Nullable DataSource targetDataSource) {
this.targetDataSource = targetDataSource;
}
}
这意味着 ListenableDataSource 在构造时,会调用父类 DelegatingDataSource.setTargetDataSource() 来保存内部的 HikariDataSource。
如果我们改写 setTargetDataSource() 方法,在保存之前先用 P6DataSource 包一层,就能实现无侵入的 DataSource 代理:
public void setTargetDataSource(@Nullable DataSource targetDataSource) {
// 原始行为:this.targetDataSource = targetDataSource;
// 改写后:
this.targetDataSource = new P6DataSource(targetDataSource);
}
这个方案的精妙之处在于:
- 不修改框架代码——改的是 Spring JDBC 的
DelegatingDataSource,框架代码不能改,但框架依赖的基础库可以 - 不改配置——不需要碰 JDBC URL 或启动参数
- 位于关键路径上——所有通过
ListenableDataSource创建的数据源都会经过这个方法 - 切入点稳定——
DelegatingDataSource是 Spring 的公开 API,跨版本兼容
找到这个切入点不是靠灵感,而是一个系统性过程:先定位目标行为的执行链路,再沿着继承链寻找可控节点。
字节码改写:三种姿势与选型
确定了"改哪里",下一步是"怎么改"。
我们需要在运行时修改 DelegatingDataSource.setTargetDataSource() 方法的行为。注意,这不是对实例做动态代理(cglib 能做的事),而是修改类定义本身——只能通过字节码改写实现。
关于运行时字节码改写的前提:JDK 9 之后支持动态 attach Agent,Byte Buddy Agent 已封装了这个逻辑,无需修改启动参数即可在运行时改写已加载的类。
以下是三种 Byte Buddy 实现方式:
方案一:类文件替换
预先编译好一个修改过的 DelegatingDataSource 类,运行时整体替换:
new ByteBuddy()
.redefine(NewDelegatingDataSource.class)
.name(DelegatingDataSource.class.getName())
.make()
.load(Thread.currentThread().getContextClassLoader(),
ClassReloadingStrategy.fromInstalledAgent());
需要在代码中维护一份完整的替换类,当 Spring 版本升级时,替换类可能与原始类不兼容。
方案二:直接操作字节码
通过 ASM 级别的 API 逐条编写字节码指令:
new ByteBuddy()
.redefine(DelegatingDataSource.class)
.method(named("setTargetDataSource"))
.intercept(MyImplementation.INSTANCE)
.make()
.load(Thread.currentThread().getContextClassLoader(),
ClassReloadingStrategy.fromInstalledAgent());
其中 MyImplementation 需要手写 ASM 字节码——visitVarInsn、visitMethodInsn、visitFieldInsn 逐行控制栈操作。可以用 IDEA 的 Byte-Code-Analyzer 插件辅助生成,但本质上仍是在操作底层指令,不可读、无法调试、维护成本极高。
方案三:Byte Buddy Advice(最终选择)
public static void redefine() {
new ByteBuddy()
.redefine(DelegatingDataSource.class)
.visit(Advice.to(Decorator.class)
.on(ElementMatchers.named("setTargetDataSource")))
.make()
.load(Thread.currentThread().getContextClassLoader(),
ClassReloadingStrategy.fromInstalledAgent()).getLoaded();
}
static class Decorator {
@Advice.OnMethodEnter
public static void enter(
@Advice.Argument(value = 0, readOnly = false)
DataSource dataSource) {
dataSource = new P6DataSource(dataSource);
}
}
Advice 的原理不是动态代理,而是直接修改方法体的字节码。上面的代码等价于在方法开头插入一行:
public void setTargetDataSource(@Nullable DataSource targetDataSource) {
targetDataSource = new P6DataSource(targetDataSource); // ← 插入的代码
this.targetDataSource = targetDataSource;
}
选型对比
| 类文件替换 | 操作字节码 | Advice | |
|---|---|---|---|
| 可读性 | 中(需维护完整类) | 低(ASM 指令) | 高(Java 注解) |
| 可调试性 | 中 | 低 | 高 |
| 维护成本 | 高(跟随 Spring 版本) | 极高 | 低 |
| 灵活性 | 高 | 极高 | 中 |
方案三是最终选择:代码可读、可调试,修改范围精确到方法级别,不依赖原类的完整实现。
两个限制需要注意:
- 动态修改已加载的类,不能添加或删除方法/字段,只能修改方法体
- Byte Buddy 的 MethodDelegation 会隐式添加字段,因此不适用于已加载类的 redefine,必须用 Advice
封装成 Starter:开箱即用
目标是让业务方零代码接入——只加一个 Maven 依赖就自动启用 SQL 监控:
<dependency>
<groupId>com.kuaishou.ad</groupId>
<artifactId>sqllog-spring-boot-starter</artifactId>
<version>制品库查询最新版</version>
</dependency>
利用 Spring Boot 的自动配置机制,Starter 在应用启动时自动执行字节码改写逻辑——既不修改业务代码,也不更改系统配置。
需要注意 Spring Boot 3.0(Spring 6.0)调整了自动配置的注册方式:从 spring.factories 改为 META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports。在实现 Starter 时需要兼容两种方式。
SQL 打印效果
启用后的 SQL 日志输出分为三行:
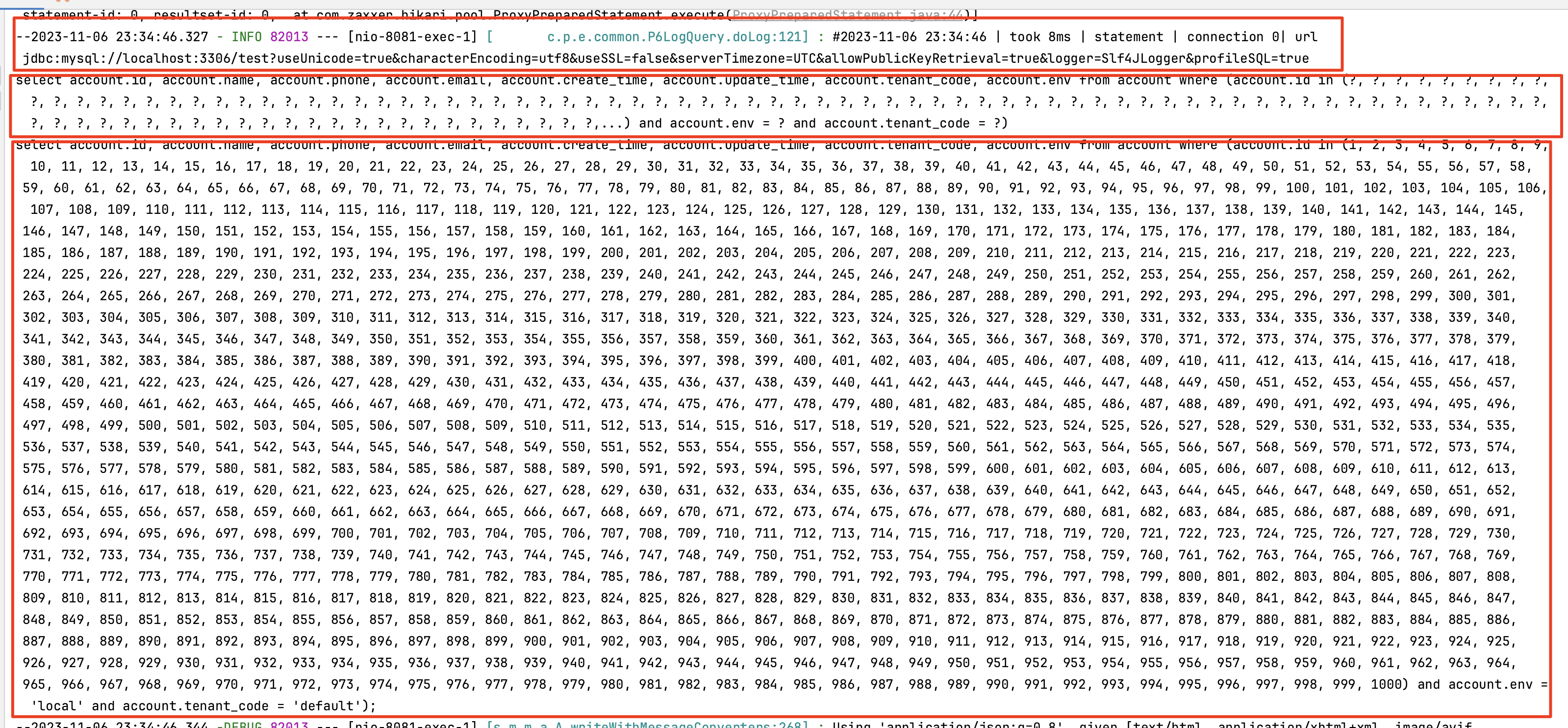
- 第一行:执行时间、耗时、SQL 操作类型、数据库连接信息
- 第二行:参数化 SQL(缩略)
- 第三行:绑定参数后的实际执行 SQL(完整)
SQL 缩略打印
回到开头提到的需求——SQL 缩略不是简单的字符串截断,而是解析 SQL 结构,仅对 IN (...) 等参数列表进行智能缩略:
-- 原始 SQL(参数列表超长)
SELECT * FROM user
WHERE id IN (1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008)
AND name IN (SELECT name FROM whitelist
WHERE name IN ('a','b','c','d','e','f','g','h','i','j','k','l','m'))
-- 缩略后(保留结构,截断参数)
SELECT * FROM user
WHERE id IN (1001, 1002, 1003, 1004, 1005, ...)
AND name IN (SELECT name FROM whitelist
WHERE name IN ('a','b','c','d','e', ...))
这一功能基于 P6Spy 的自定义 MessageFormattingStrategy 实现:通过正则匹配 SQL 中的参数列表区域(如 IN (...) 内的逗号分隔值),对超过阈值的列表进行截断并追加省略标记。参数化 SQL 做缩略方便快速定位问题,绑定参数后的完整 SQL 保持原样以便直接复制到数据库执行。
方法论提炼:寻找代理切入点
回过头看,这个问题的具体技术细节(Byte Buddy、P6Spy、Spring Boot Starter)都不是核心——核心是在不修改外部代码的前提下,找到一个可拦截的切入点。
这套思路可以复用到任何"第三方组件无法修改但需要增强"的场景:
1. 目标行为在哪里发生?
→ 找到执行链路(DAO → ORM → DataSource → Connection → Driver)
2. 在链路上,哪个节点是我能控制的?
→ 逐一排除约束(URL 归 DBA → 排除 Driver/Connection → 只剩 DataSource)
3. 这个节点的创建过程可以被拦截吗?
→ 分析对象构造路径,沿继承链寻找可注入点
→ 框架代码不能改,但框架依赖的基础库可以
4. 用什么手段注入?
→ 按成本/侵入性排序:配置 < 代理 < 字节码
→ 在可行方案中选择成本最低的
本文的解法是一个特定实例,但这套决策路径是通用的。下次遇到"这段代码我不能碰,但我需要改变它的行为"时,不妨沿着这条路径走一遍——答案往往藏在继承链或依赖关系图的某个节点上。