微服务系列(二):拆分策略与实践
前面我们学习了微服务的全景架构,了解到相对于传统单体架构,微服务的优势,以及系统服务化的发展趋势。
对于新启动的项目,我们在权衡之后可以大方的使用微服务架构。但其实大部分情况下,我们还要去维护一些以前研发的单体系统,这些系统可能因为访问流量的膨胀、功能的扩张而显得非常臃肿不堪,急需要向微服务架构迁移。
微服务迁移准备
1、代码重构和标准化
在启动拆分之前,需要先对现有代码进行梳理和标准化。这包括统一编码规范、消除重复代码、理清模块间的依赖关系。如果代码本身混乱不堪,贸然拆分只会把混乱从一个单体扩散到多个服务中。
2、数据库分离准备
微服务的核心原则之一是每个服务拥有自己的数据存储。在迁移前需要分析现有数据库中的表关系、跨表 JOIN 查询和存储过程,制定数据拆分方案。数据层的耦合往往是微服务拆分中最大的障碍,提前规划能显著降低后期风险。
3、接口标准化(REST/RPC 协议统一)
服务间通信需要统一的协议和接口规范。团队应提前确定采用 RESTful API 还是 gRPC 等 RPC 框架,并建立接口版本管理、数据序列化格式(如 JSON、Protocol Buffers)等标准。接口标准化是服务间可靠通信的基础。
4、监控体系搭建
微服务架构下,服务数量成倍增长,没有完善的监控体系将无法定位问题。需要建立包括基础设施监控(CPU、内存、网络)、应用性能监控(APM)、日志聚合和链路追踪(如 SkyWalking、Jaeger)在内的立体化监控能力。
5、自动化部署流水线
微服务意味着更多的部署单元和更高的发布频率,手动部署将成为严重瓶颈。需要提前搭建 CI/CD 流水线,实现从代码提交到构建、测试、部署的全流程自动化,确保每个服务都能独立、快速地完成发布。
6、DevOps 文化建设
微服务不仅是技术架构的变革,更是组织协作方式的转变。团队需要具备持续集成和持续交付的能力,开发、测试和运维之间的壁垒需要打破。同时还要建立对问题和故障的快速响应机制,做到"谁构建、谁运行"。
7、团队组织调整(康威定律)
康威定律指出,系统架构往往是组织沟通结构的映射。服务的拆分需要符合团队结构,或者能够逆向推动组织架构的调整(逆康威定律)。每个微服务最好由一个小型全功能团队负责,这样才能保证服务边界清晰、迭代高效。
AKF 扩展立方体:拆分的理论框架
在讨论具体的拆分策略之前,我们先从 Martin L. Abbott 所著《架构即未来》中介绍的 AKF 扩展立方体出发,建立一个宏观的扩展性认知框架。
AKF 扩展立方体(Scalability Cube)是一种可扩展模型,这个立方体有三个轴线,每个轴线描述扩展性的一个维度,分别是:
- X 轴:代表无差别的克隆服务和数据,工作可以很均匀的分散在不同的服务实例上
- Y 轴:关注应用中职责的划分,比如数据类型、交易执行类型的划分
- Z 轴:关注服务和数据的优先级划分,如分地域划分
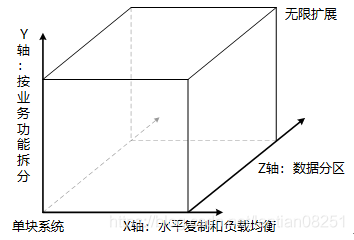
以上 X、Y 和 Z 轴的划分可以概括为:X 轴关注水平复制,Z 轴类似数据分区,而 Y 轴则强调基于不同的业务拆分。理论上按照这三个扩展维度,可以将一个单体系统进行无限扩展。
举例来说,比如用户预约挂号应用,一个集群撑不住时,分了多个集群,后来用户激增还是不够用,经过分析发现是用户和医生访问量很大,就将预约挂号应用拆成了患者服务、医生服务、支付服务等三个服务。三个服务的业务特点各不相同,独立维护,各自都可以再次按需扩展。
在 AKF 模型中,Y 轴就是我们所说的微服务的拆分模式,即基于不同的业务进行拆分。但在进行业务拆分过程中,我们发现业务往往与数据有较大耦合性,所以接下来我们把业务和数据结合起来,从多个维度展开讨论具体的拆分策略。
业务与数据:拆分的两大维度
服务拆分存在两大维度,即业务与数据。业务体现在各种功能代码中,通过确定业务的边界,并使用领域与界限上下文、领域事件等技术手段可以实现拆分。而数据的拆分则体现在如何将集中式的中心化数据转变为各个微服务各自拥有的独立数据,这部分工作同样十分具有挑战性。
关于业务和数据谁应该先拆分的问题,可以是先数据库后业务代码,也可以是先业务代码后数据库。然而在拆分中遇到的最大挑战可能会是数据层的拆分,因为在数据库中,可能会存在各种跨表连接查询、跨库连接查询以及不同业务模块的代码与数据耦合得非常紧密的场景,这会导致服务的拆分非常的困难。因此在拆分步骤上我们更多的推荐数据库先行。数据模型能否彻底分开,很大程度上决定了微服务的边界功能是否彻底划清。
微服务颗粒的拆分策略
微服务拆分没有一个绝对的标准答案,服务拆分的粒度需要根据业务场景来规划,而随着业务的发展,原先的架构方案也需要做调整。
虽然没有固定的套路,但是我们在业务实践过程中总结的一些经验,以做参考。
基于业务逻辑拆分
基于业务逻辑拆分相对好理解一点,典型的单一职责原则,我们将功能相近的业务整合到一个服务颗粒上。比如一个办公领域系统,考勤、工作流、音视频会议是是三个截然不同的业务领域,这可能就是我们拆分的一个入手点。
领域模型拆分
领域驱动设计DDD(Domain-Driven Design 领域驱动设计)是一个很简单的概念,表示我们对系统的划分是基于领域的,也即是基于业务方向去思考的。
举一个典型的电商业务例子。电商的业务体系庞大,涉及各方面的细节。但是我们大概能够根据业务的职能做一个拆分,比如阿里的电商中台业务,包含 用户账号子系统、商品子系统、订单子系统、客户子系统、物流子系统 等。
因为职能不同,这些领域之间包含清晰的界限,所以我们可以按照这个方向将服务于不同领域(商品域和订单域)的子系统拆成独立的服务颗粒。如下图:
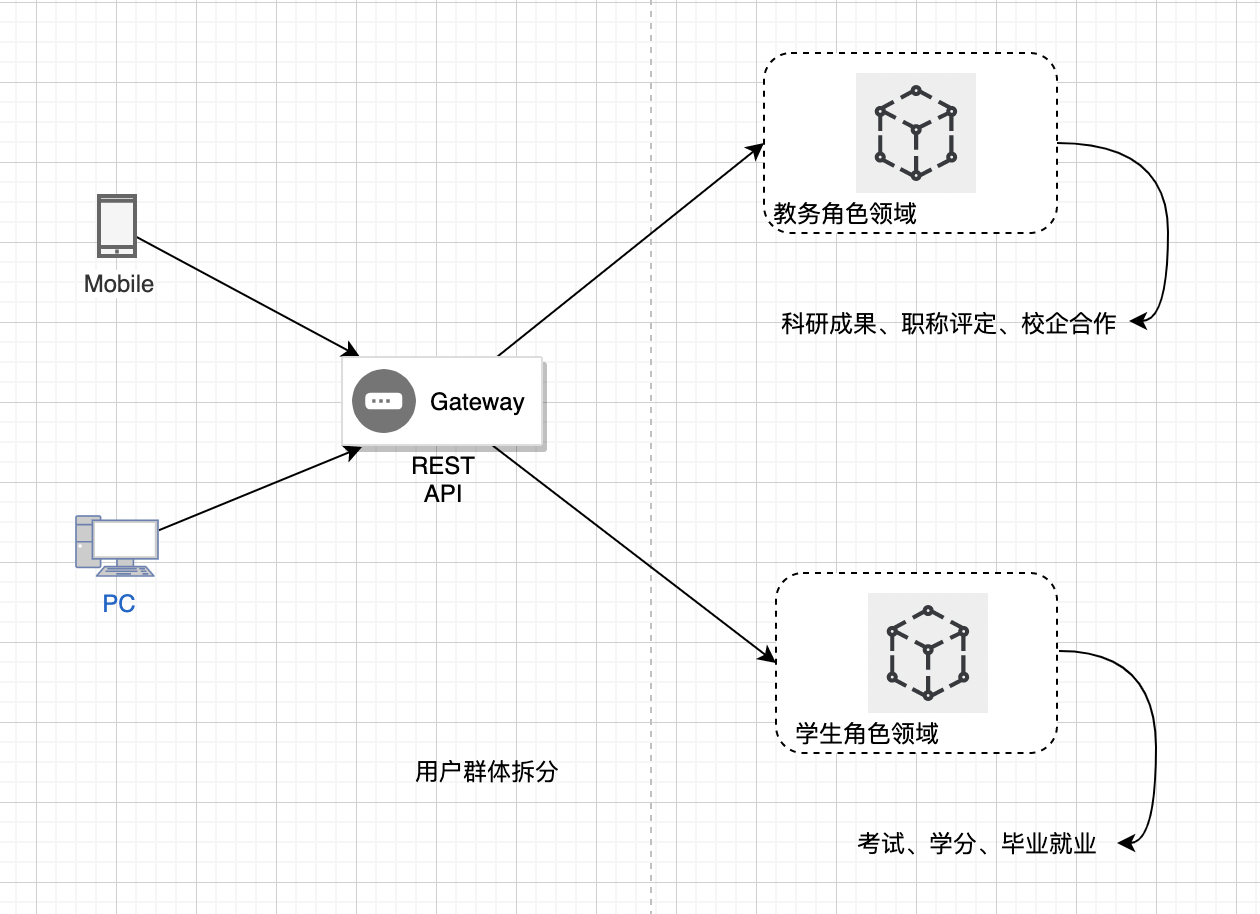
用户群体拆分
根据用户群体做拆分,我们首先要了解自己的系统业务里的用户角色领域是否没有功能耦合,有清晰的领域界限。
比如教育信息化系统,教师的业务场景和学生的业务场景,基本比较独立,而且拆分后流量上有明显的削弱,这时候结合具体的业务分析,看是否有价值。如下图所示:
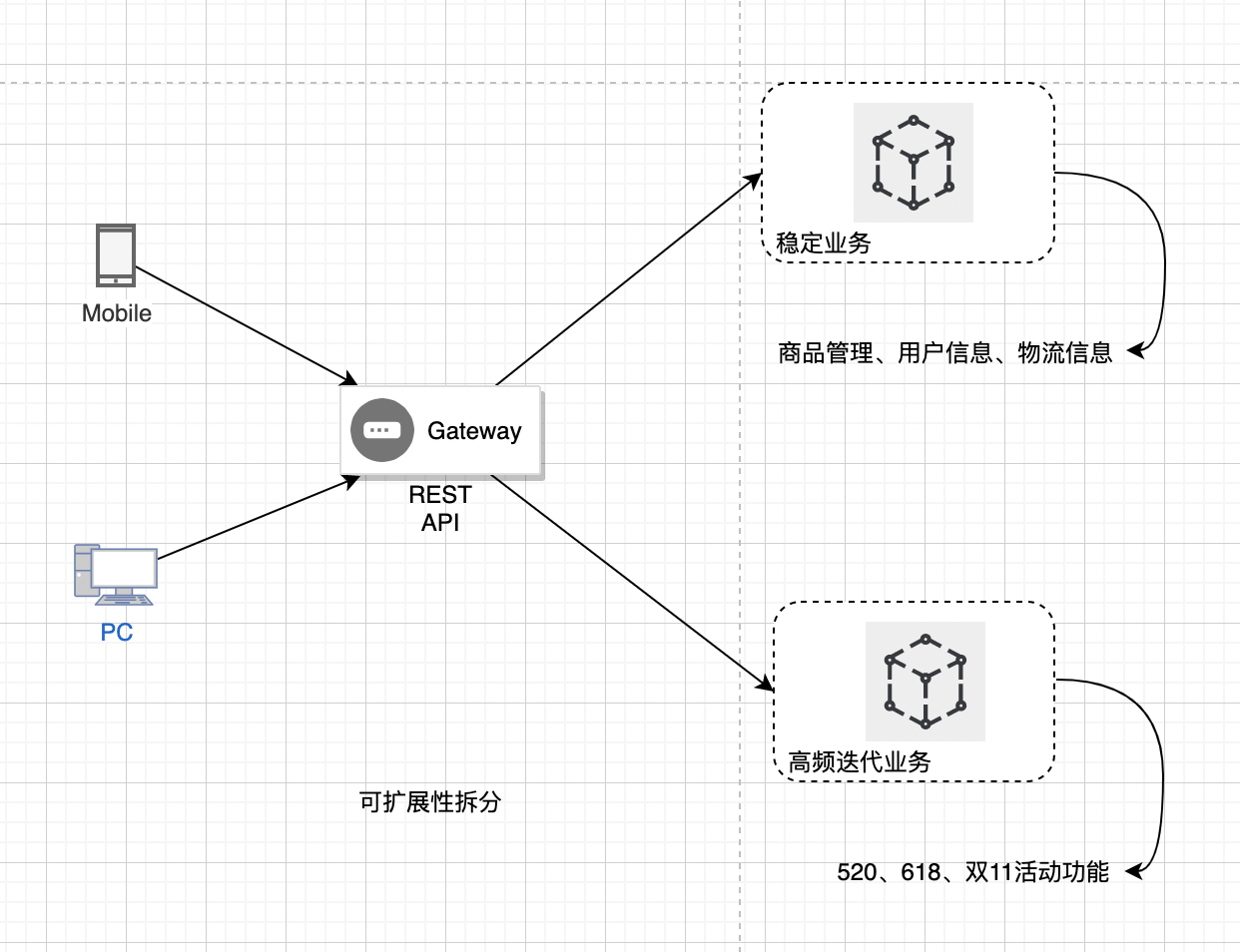
基于可扩展拆分
这个需要区分系统中变与不变的部分,不变的部分一般是成熟的、通用的服务功能,变的部分一般是改动比较多、满足业务迭代扩展性需要的功能,我们可以将不变的部分拆分出来,作为共用的服务,将变的部分独立出来满足个性化扩展需要。同时根据二八原则,系统中经常变动的部分大约只占 20%,而剩下的 80% 基本不变或极少变化,这样的拆分也解决了发布频率过多而影响成熟服务稳定性的问题。比如一个电商领域的系统,用户信息、基本商品信息、物流信息 等模块的管理能力和视图界面,一般是比较稳定的;而类似运营活动的功能和页面一般是经常变化的(520、618、双11),会有不同的活动策略和视图界面,需要经常迭代发布。如下图所示
基于可靠性拆分
核心模块拆分
我们团队在做MySQL数据库和Redis集群拆分的时候,总会把一些重要的模块独立放在一个集群上,不与其他模块混用,而这个独立的集群,服务机性能要是最好的。这样做的目的是,当重要度较低的模块发生故障时,不会影响重要度高的模块。
同要的道理,我们会将 账号信息、登录信息、服务中心等重要度最高的要害模块单独拆分在一个服务颗粒上(因为这类模块不可用之后,整个系统基本完全瘫痪),再做成服务集群,来保障它的高可用。 如下图所示:
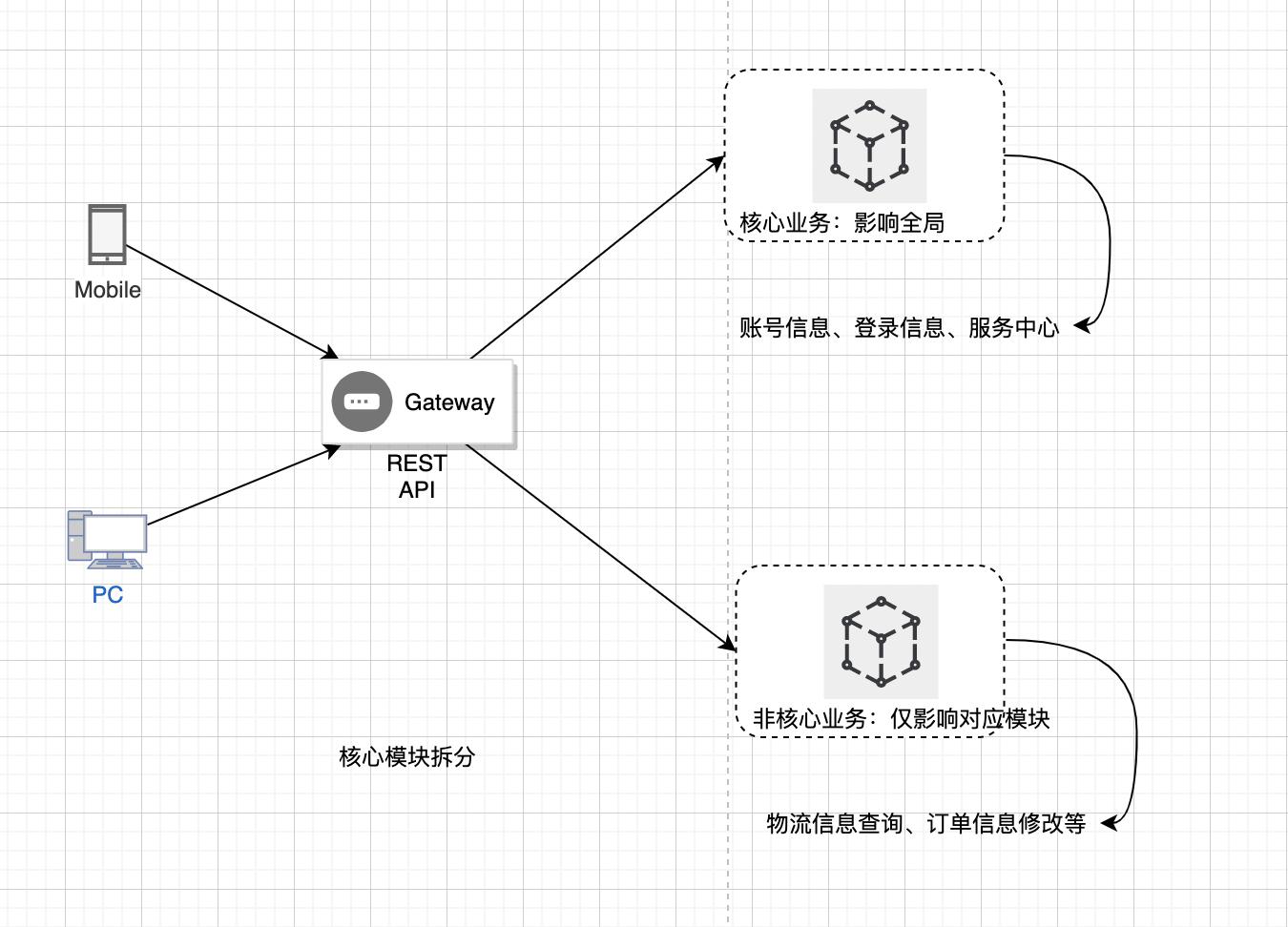
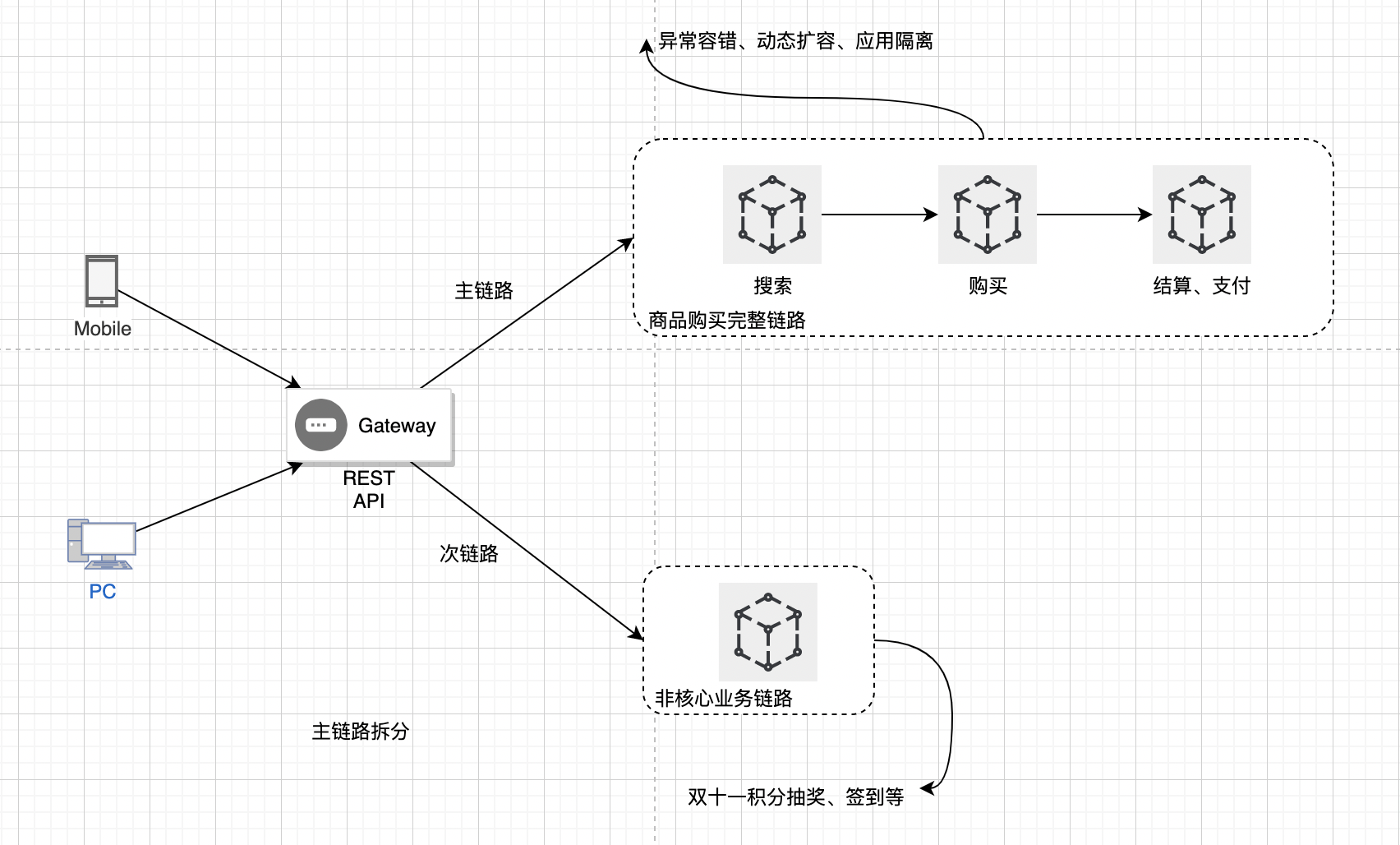
主次链路拆分
在各个业务系统中,其实都会有主次业务链路。主业务链条,完成了业务系统中最核心的那部分工作。而次链路是保证其他基础功能的稳定运行。
以电商为例子:商品搜索->商品详情页->购物车模块->订单结算->支付业务,就是一条最简单的主链路。主链路是整个系统的核心主战场,最好的资源跟火力都要放在这里,保证不失守。
一个系统一般有多条核心链路和多条次链路,互相支持构成一个完整的系统。而我们将主次链路进行拆分,主要为了以下几个目标。
异常容错
为主链路建立层次化的降级策略(多级降级),以及合理的熔断策略。主流容错框架如 Sentinel(阿里开源,支持流量控制、熔断降级、系统保护等)和 Resilience4j(轻量级、函数式风格,适合 Spring Boot 生态)都提供了完善的降级和熔断能力。
计算资源分配
主链路通常来讲都是高频场景,自然需要更多的计算资源,最主要的体现就是集群里分配的虚机数量多。比如电商场景中特惠专场抢购等。
但是无论是虚机的分配,还是kubernetes的动态扩缩容,应该都需要单独优待,如资源分配倾斜,独立治理等。
服务隔离
主链路是高频且核心的主业务模块,把主链路的服务与其他起辅助作用的业务服务隔离开来,避免次链路服务的异常情况影响到主链路服务。
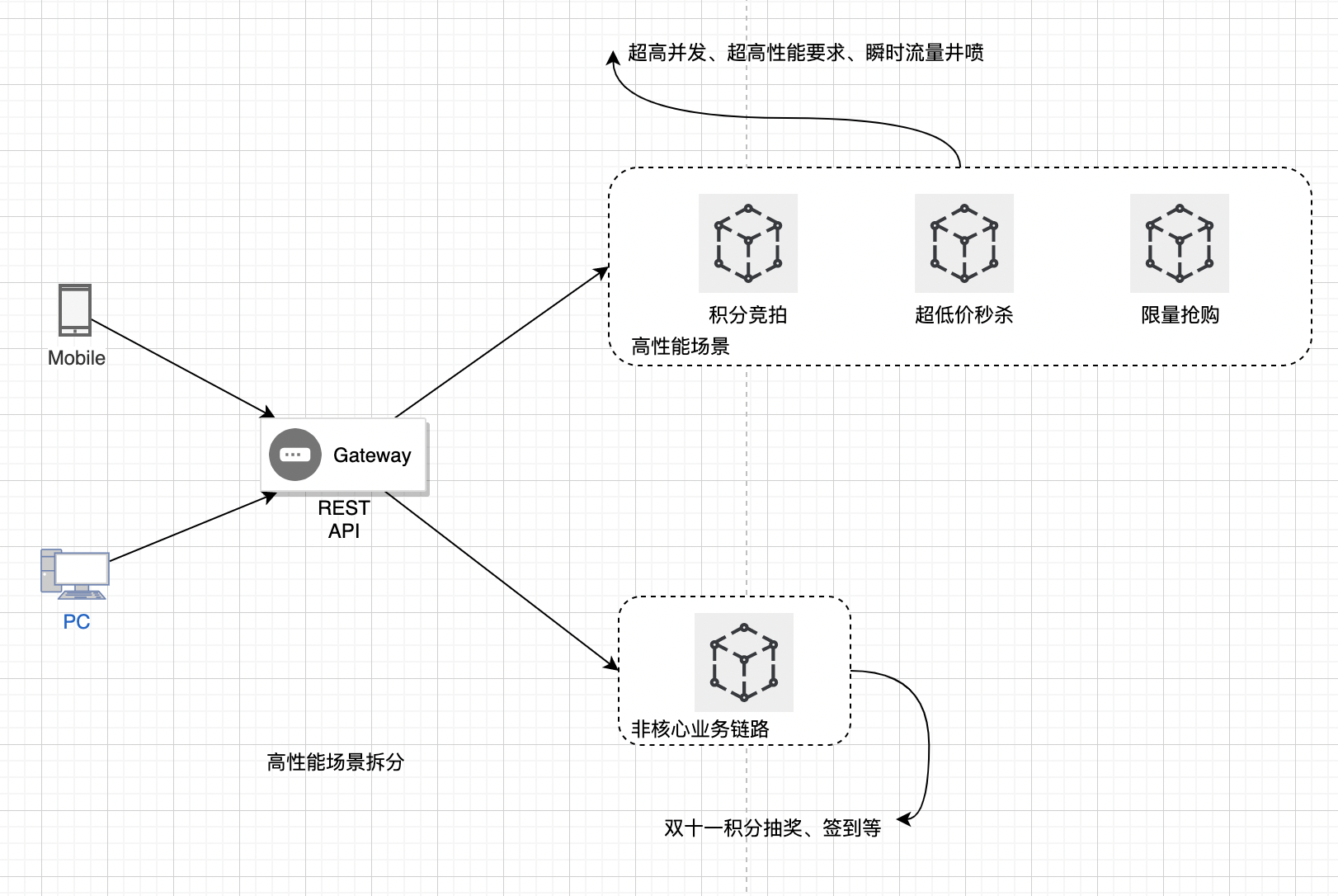
基于性能需求拆分
根据性能需求来进行拆分。简单来说就是访问量特别大,访问频率特别高的业务,又要保证高效的响应能力,这些业务对性能的要求特别高。比如积分竞拍、低价秒杀、限量抢购。
我们要识别出某些超高并发量的业务,尽可能把这部分业务独立拆分出来。这么做的原因非常简单,一个保证满足高性能业务需求,另一个保证业务的独立性,不互相影响。
类似积分竞拍、超低价秒杀、限量抢购,对瞬间峰值和计算性能要求是非常高的。这部分的业务如果跟其他通用业务放在一块,一个是可能互相影响,比如某个链路阻塞,会导致雪崩沿调用链向上传递。
另外一个是如果多个业务耦合在一块,发布频率变高、服务扩缩容变难、维护复杂度变高。
实例:电商单体的拆分路径
以一个典型的电商单体系统为例,综合运用上述策略来规划拆分。首先基于业务逻辑,按领域模型将系统拆分为商品服务(商品信息、库存管理)、订单服务(下单、订单状态流转)、支付服务(支付渠道对接、交易记录)和用户服务(注册登录、用户画像)四个核心服务。接着基于可靠性,将用户服务和支付服务识别为高优先级模块,部署在独立集群并配置更高的资源配额。然后基于性能需求,将秒杀、抢购等瞬时高并发场景从订单服务中独立出来,作为单独的秒杀服务进行针对性优化(如预扣库存、异步下单)。最后基于可扩展性,将促销活动、优惠券等频繁变动的运营功能与相对稳定的商品基础信息服务分离,使两者可以按各自节奏独立迭代发布。
迁移模式:绞杀者与修缮者
了解了拆分策略后,还需要选择合适的迁移模式将策略落地。服务拆分的方法需要根据系统自身的特点和运行状态,通常分为绞杀者与修缮者两种模式。
绞杀者模式
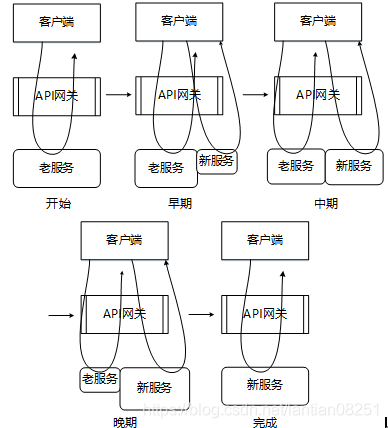
绞杀者模式(Strangler Pattern)最早由 Martin Fowler 提出,指的是在现有系统外围将新功能用新的方式构建为新的服务的策略,通过将新功能做成微服务方式,而不是直接修改原有系统,逐步的实现对老系统替换。采用这种策略,随着时间的推移,新的服务就会逐渐"绞杀"老的系统。对于那些规模很大而又难以对现有架构进行修改的遗留系统,推荐采用绞杀者模式。
绞杀者模式的示意图如下图所示,我们可以看到随着功能演进和时间的不断推移,老的遗留系统功能被逐步削弱,而采用微服务架构的新功能越积越多,最终会形成从量变到质变的过程。绞杀者模式在具体实施过程中,所需要把握的最主要一点原则就是对于任何需要开发的功能一定要完整的采用微服务架构,对于完全独立的新功能这点比较容易把握,而对于涉及到老业务变更的新功能则需要通过重构达到这一目标。
修缮者模式
修缮者模式就如修房或修路一样,将老旧待修缮的部分进行隔离,用新的方式对其进行单独修复。修复的同时,需保证与其他部分仍能协同功能。从这种思路出发,修缮者模式更多表现为一种重构技术。修缮者模式在具体实现上可以参考 Martin Fowler 的 Branch By Abstraction 重构方法,该重构方法的示意图如下图所示。
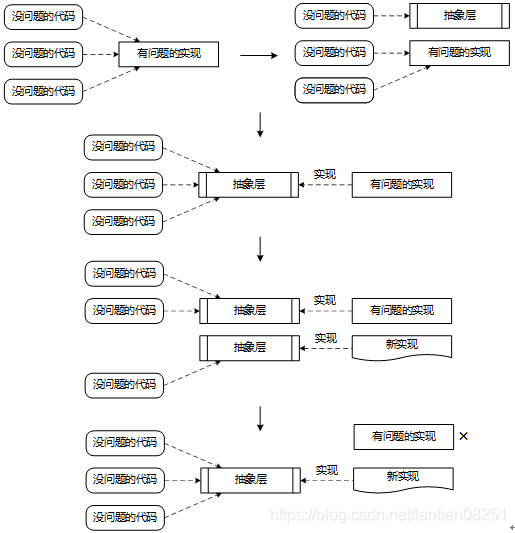
从上图中,可以看到这种模式的实现方式可以分成三个主要步骤。
- 抽象层提取:首先通过识别内部的待拆分功能,对其增加抽象接口层,同时对原有代码进行改造,确保其同样实现该抽象层。这样在依赖关系上就添加了一个中间层。
- 抽象层实现:为抽象层提供新的实现,新的实现采用微服务方式。
- 抽象层替换:采用新的实现对原有的各个抽象层实现进行逐步替换,直至原有实现被完全废弃,从而完成新老实现方式之间的替换。
总结拆分原则
- 先少后多(微服务数量)、先粗后细(粒度)
- 基于业务逻辑进行拆分(用户群体、业务领域等模型)
- 基于可靠性(核心模块独立化、主次链路隔离)
- 基于性能拆分(独立拆分高性能场景)
- 接口需保证幂等
- 接口数据定义严禁内嵌,透传
- 规范化工程结构,符合微服务风格
- 不止对计算服务进行拆分,服务层 -> 缓存层 -> 数据层 的逐步拆解,才能发挥最大功效
- 数据库先行拆分,数据模型能否彻底分开决定了微服务边界是否划清
- 迁移模式选择:大型遗留系统推荐绞杀者模式,局部重构推荐修缮者模式