异地多活架构:跨地域高可用系统的设计与演进
多地多机房部署是互联网系统的必然发展方向。一个系统要走到这一步,必然要面对流量调配、数据拆分、网络延时、架构升级等一系列问题。尽管可采用的部署架构有很多,做法也各不相同,但反观国内大型互联网公司,真正做到异地多活的能有几个?本文从最简单的单机架构出发,沿着可用性不断提升的脉络,逐步推演出异地多活架构的完整面貌,并结合阿里单元化方案解析工业级落地实践。
为什么需要异地多活?
什么是异地多活?归纳起来就是分布在异地的多个站点同时对外提供服务。多活和双活的区别是什么?其实就是提供服务的机房数量多少的区别——一个是多个机房同时提供服务,一个是两个机房同时提供服务。但如果前面加了"同城"还是"异地"那就意味着有本质的区别,技术难度也有天壤之别。
了解异地多活需要从架构设计的原则来谈。一个好的软件架构应当遵循三个核心原则:高性能、高可用、易扩展。其中高性能意味着系统要能处理更大的业务流量、更低的响应延迟;易扩展表示系统能以最小的代价去扩展,比如系统遇到大流量压力时可以在不改动代码的前提下进行扩容。
而高可用通常用两个指标来衡量:
| 指标 | 含义 |
|---|---|
| MTBF(Mean Time Between Failure) | 两次故障的间隔时间,越长说明系统越稳定 |
| MTTR(Mean Time To Repair) | 故障恢复时间,越短说明对用户影响越小 |
可用性的计算公式为:可用性(Availability)= MTBF / (MTBF + MTTR) × 100%
通常用"N 个 9"来描述系统的可用性等级:
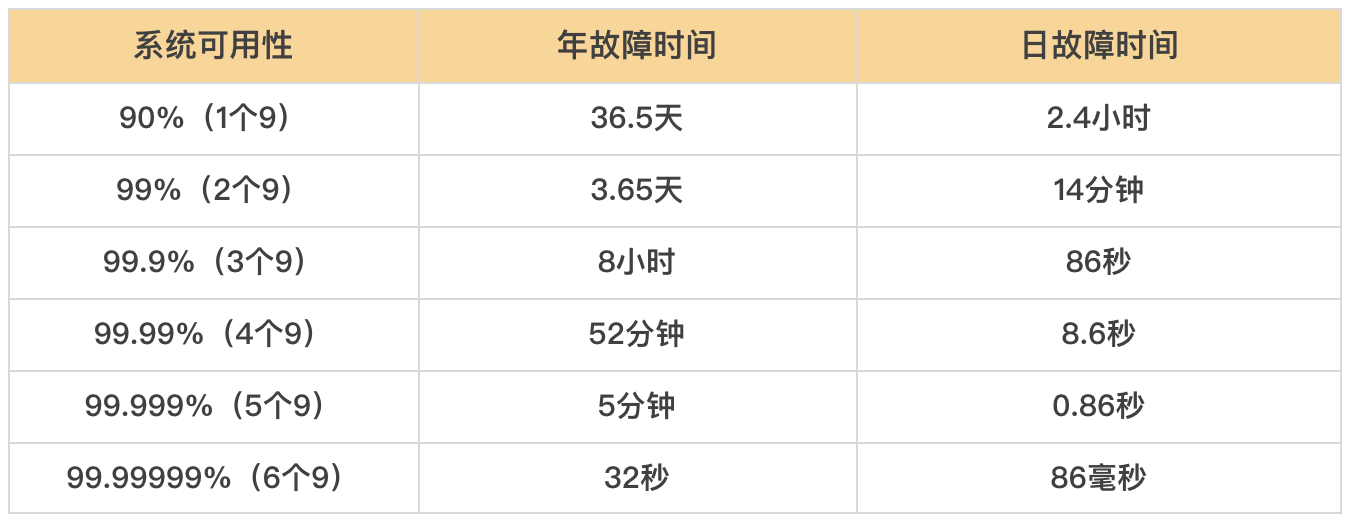
要达到 4 个 9 以上的可用性,平均每天的故障时间必须控制在 10 秒以内。故障时间越短,系统可用性越高,每提升 1 个 9,都对系统设计提出更高的要求。
然而故障是不可避免的,尤其对于现在的互联网系统,发生问题的概率很大。这些故障一般体现在三个方面:
- 硬件故障:交换机、路由器、磁盘等硬件损坏
- 软件问题:代码 Bug、配置错误、依赖服务异常
- 不可抗力:地震、水灾、火灾、停电、光缆被挖断
这些风险随时都有可能发生,历史上不乏惨痛的教训:
| 时间 | 事件 | 影响 |
|---|---|---|
| 2013.07 | 微信因市政施工导致光缆被挖断 | 宕机数小时 |
| 2015.05 | 杭州光纤被挖断 | 近 3 亿用户约 5 小时无法访问支付宝 |
| 2021.07 | B站部分服务器机房故障 | 整站持续 3 小时无法访问 |
| 2021.10 | 富途证券机房电力闪断 | 用户 2 小时无法登录和交易 |
不同体量的系统关注的重点不同:体量小时关注用户增长,这个阶段获取用户是一切;等用户体量上来了,会重点关注性能,优化接口响应时间、页面打开速度,这个阶段更多关注用户体验;等体量再大到一定规模后,可用性就变得尤为重要。像微信、支付宝这种全民级应用,如果机房发生一次故障,影响范围是非常巨大的。对于全民级应用而言,再小概率的风险也不能忽视——这就是异地多活存在的根本原因。
一句话总结:异地多活的本质驱动力,是随着系统体量增长,可用性从"锦上添花"变成了"生死攸关"。
部署架构的演进历程
第一阶段:单机架构
最简单的模型:客户端请求 → 业务应用 → 单机数据库 → 返回结果。

数据库单机部署,一旦遭遇意外,所有数据全部丢失。如何避免这个问题?最直接的方案就是做备份——对数据库文件定期复制到另一台机器上,这样即使原机器丢失数据,依旧可以通过备份恢复。
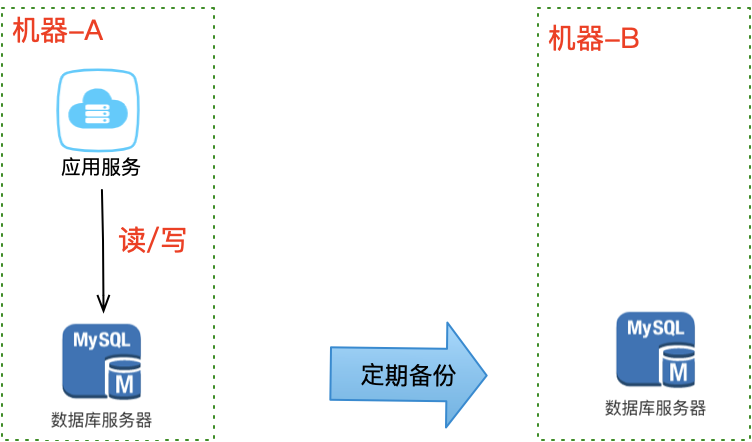
但这种方案存在两个问题:
- 恢复需要时间:业务需先停机再恢复数据,停机时间取决于数据量
- 数据不完整:因为是定期备份,数据肯定不是最新的,完整程度取决于备份周期
数据库越大,故障恢复时间越长,这种方案可能连 1 个 9 都达不到。有没有更好的方案呢?如果你对 MySQL 有了解的话,可能立即想到数据库的主从副本。
第二阶段:主从副本
在另一台机器上部署数据库从库(slave),与主库(master)保持实时同步。
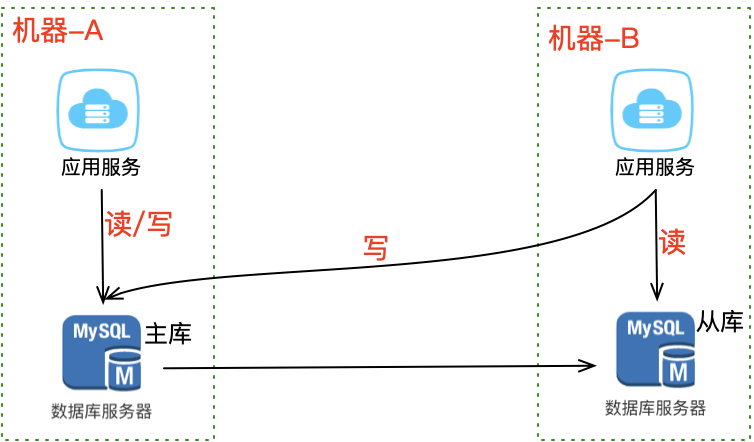
这个方案的优点在于:
| 优势 | 说明 |
|---|---|
| 数据完整性高 | 主从实时同步,数据差异极小 |
| 抗故障能力提升 | 主库异常时从库可切换为主库 |
| 读性能提升 | 业务可直接读从库,分担主库压力 |
不仅大大提高了数据库的可用性,还提升了系统的读性能。
提升系统可用性的关键就是冗余——担心一个实例故障就部署多个实例,担心一台机器宕机就部署多台机器。
第三阶段:同城灾备
作为一个技术规划者,面对技术方案什么时候都要往最坏处去想,不能觉得某个场景发生问题的几率很小就放过。机房级别的风险虽然概率小,但一旦发生影响巨大。应对方案就不能局限在一个机房内了——需要在同城再搭建一个机房,用专线网络连通。原机房叫 A 机房,新机房叫 B 机房。有了新机房怎么把它用起来?这里还要考虑数据风险。
冷备
为了避免 A 机房故障导致数据丢失,最简单的方案还是备份——A 机房的数据定时在 B 机房做备份。B 机房只做数据备份,不提供实时服务,只在 A 机房故障时才启用。为什么叫冷备?因为 B 机房是"冷"的,只有 A 机房故障时才会启用。
- 优点:数据有异地备份
- 缺点:数据不完整、恢复期间业务不可用
热备
备份的问题依旧和之前一样:数据不完整、恢复数据期间业务不可用。所以我们还是需要用主从副本的方式,在 B 机房部署 A 机房的数据副本,这样就算整个 A 机房挂掉,B 机房也有比较完整的数据。
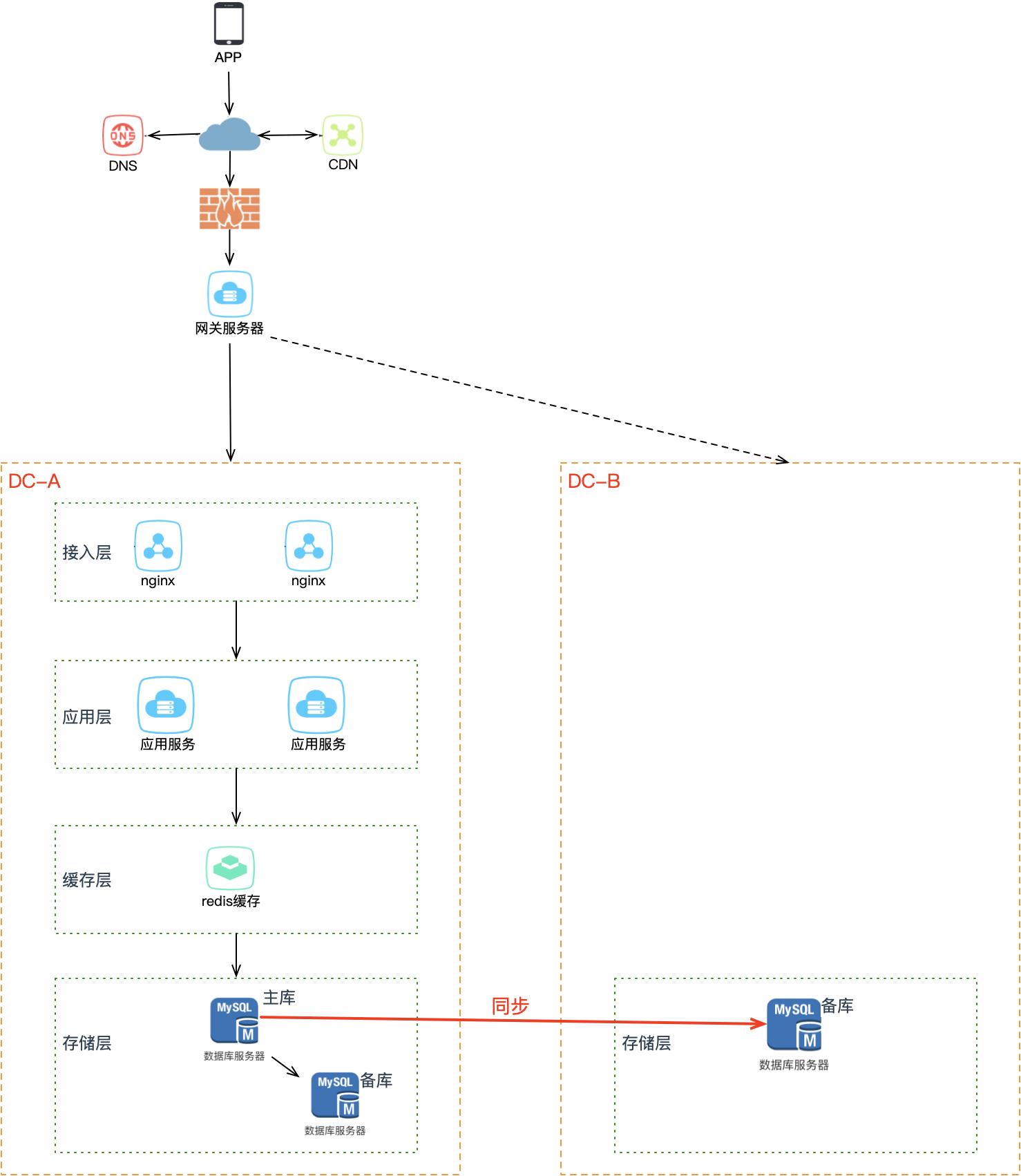
数据是保住了,但这时需要考虑另一个问题:如果 A 机房真挂掉了,要想保证服务不中断,你还需要在 B 机房紧急做这些事情:B 机房所有从库提升为主库、部署应用启动服务、部署接入层配置转发规则、DNS 指向 B 机房接入流量。整个过程需要人为介入,且需花费大量时间来操作,恢复之前整个服务还是不可用的。
因此要想缩短业务恢复的时间,就必须把这些工作在 B 机房提前做好——不仅要在 B 机房部署 A 机房的数据副本,还要提前部署好接入层、业务应用。B 机房完整镜像 A 机房,从最上层的接入层到中间的业务应用到最下层的存储,全部部署就位,处于待命状态。
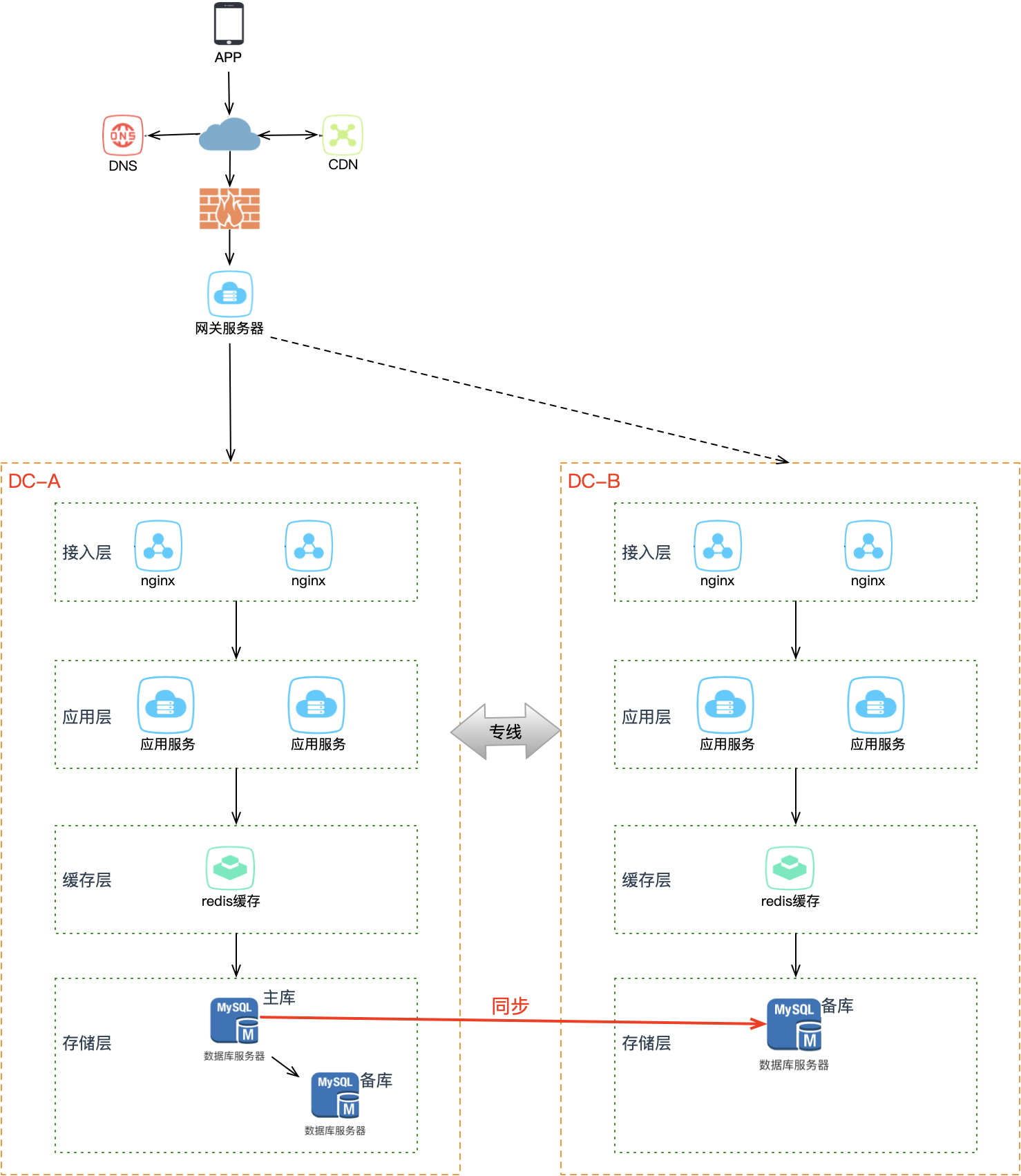
这样 A 机房整个挂掉,只需做两件事:B 机房所有从库提升为主库,DNS 指向 B 机房接入流量。热备相比冷备最大的优点是:随时可切换。
无论冷备还是热备,B 机房都处于备用状态,统称为同城灾备。它解决了机房级别的故障问题,可用性再次提升,但有一个隐患——B 机房从未经历过真实流量的考验,真的把全部流量切过去,不敢百分百保证它能正常工作。
第四阶段:同城双活
从成本角度看,新部署一个机房需要购买服务器、带宽资源,花费成本非常高昂,只让它当一个后备军确实浪费。因此我们需要让 B 机房也接入流量、实时提供服务,好处有二:
- 实时训练后备军:让 B 机房达到与 A 机房相同的"作战水平",随时可切换
- 分担流量压力:B 机房接入流量后,减轻 A 机房的负载
但 B 机房的存储是 A 机房的从库,默认不可写。B 机房的写请求打到本机房存储上肯定会报错。解决方案是在业务应用层做读写分离改造:
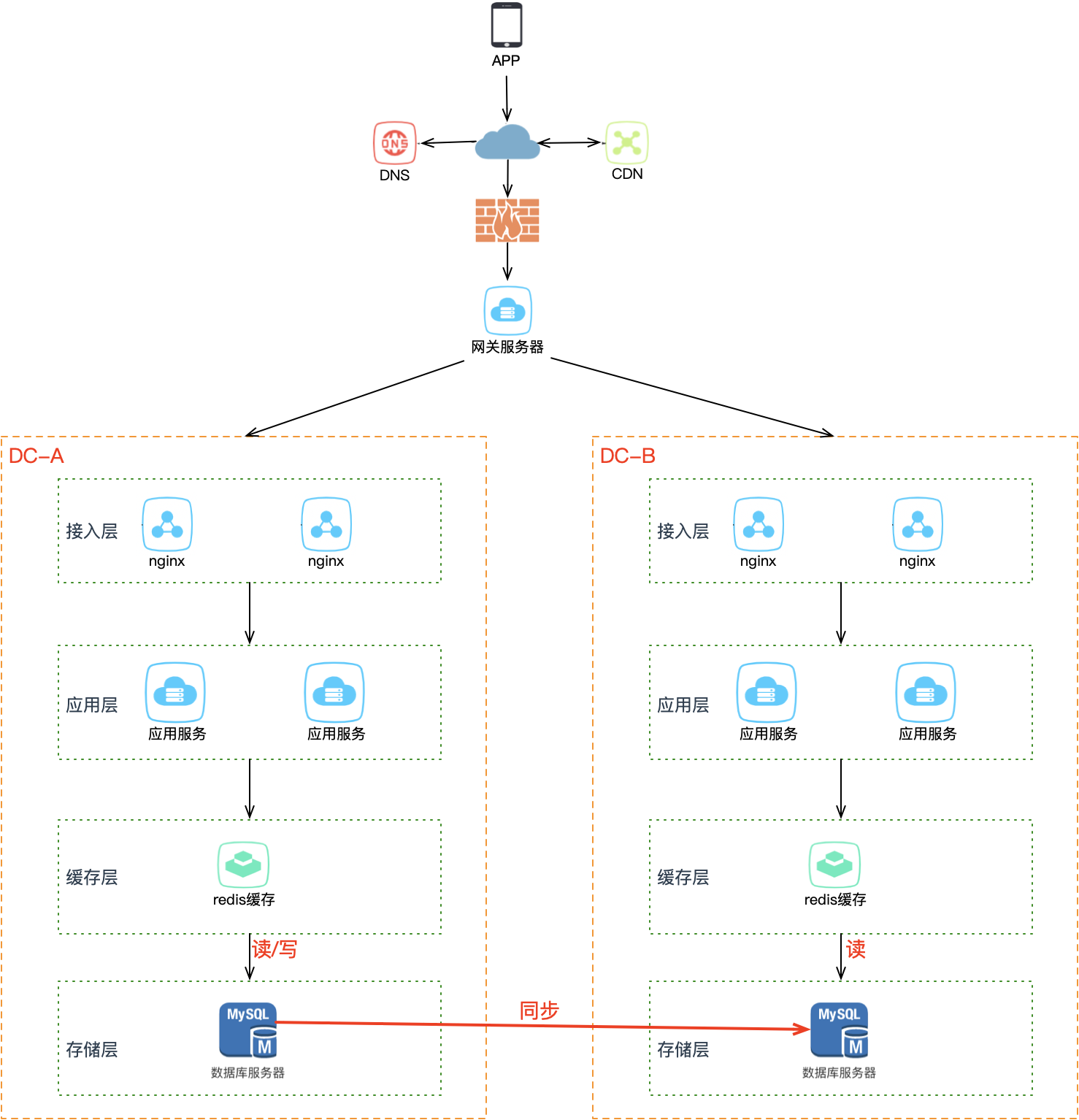
| 操作 | 路由策略 |
|---|---|
| 读请求 | 可读任意机房的存储 |
| 写请求 | 只允许写 A 机房(主库所在) |
这会涉及到所有存储——MySQL、Redis 等都需要区分读写请求,有一定的业务改造成本。A 机房的存储都是主库,所以 A 是主机房,B 是从机房。
两个机房部署在同城,物理距离近,专线网络延迟可接受。业务改造完成后,B 机房可以从 10% → 30% → 50% → 100% 逐步接入流量,持续观察是否存在问题,逐渐让 B 机房的工作能力达到和 A 机房相同水平。现在 B 机房实时接入了流量,如果 A 机房挂了,就可以大胆地把 A 的流量全部切到 B 机房,完成快速切换。
同城双活比灾备更进一步:B 机房实时接入流量,且能应对随时的故障切换,系统弹性大大增强。在逻辑上我们是把两个机房看做一个整体来规划的,相当于把 2 个机房当作 1 个机房来用。
值得一提的是,在阿里内部,同城双活的整个模式应用层是双活的,两边的业务都有,但存储层都是主备或者本身的高可用模式——主在 A 机房、备在 B 机房,不会同时用。严格意义上来讲这是"伪同城双活",因为数据层不是真正意义的双活。但在 2020 年的双 11,交易链路由于中心单元流量占比较大,一些核心服务(如下单服务)中心单元做了同城双活。这说明一个问题:并不是技术达不到,有时候部署方案需要综合考虑资源成本问题。
但两个机房在物理上仍处于同一城市。如果整个城市发生自然灾害(如 2021 年河南水灾),两个机房依旧存在全局覆没的风险。
第五阶段:两地三中心
为了应对城市级别的灾难,这次冗余机房就不能部署在同一个城市了,需要把它放到距离更远的地方——部署在异地。通常建议两个机房的距离要在 1000 公里以上,这样才能应对城市级别的灾难(如果两个机房的距离到不了 1000 公里以上就不算异地部署)。假设 A、B 机房在北京,新部署的 C 机房放在上海,最简单的方案还是做冷备,定时把 A、B 机房的数据在 C 机房做备份。
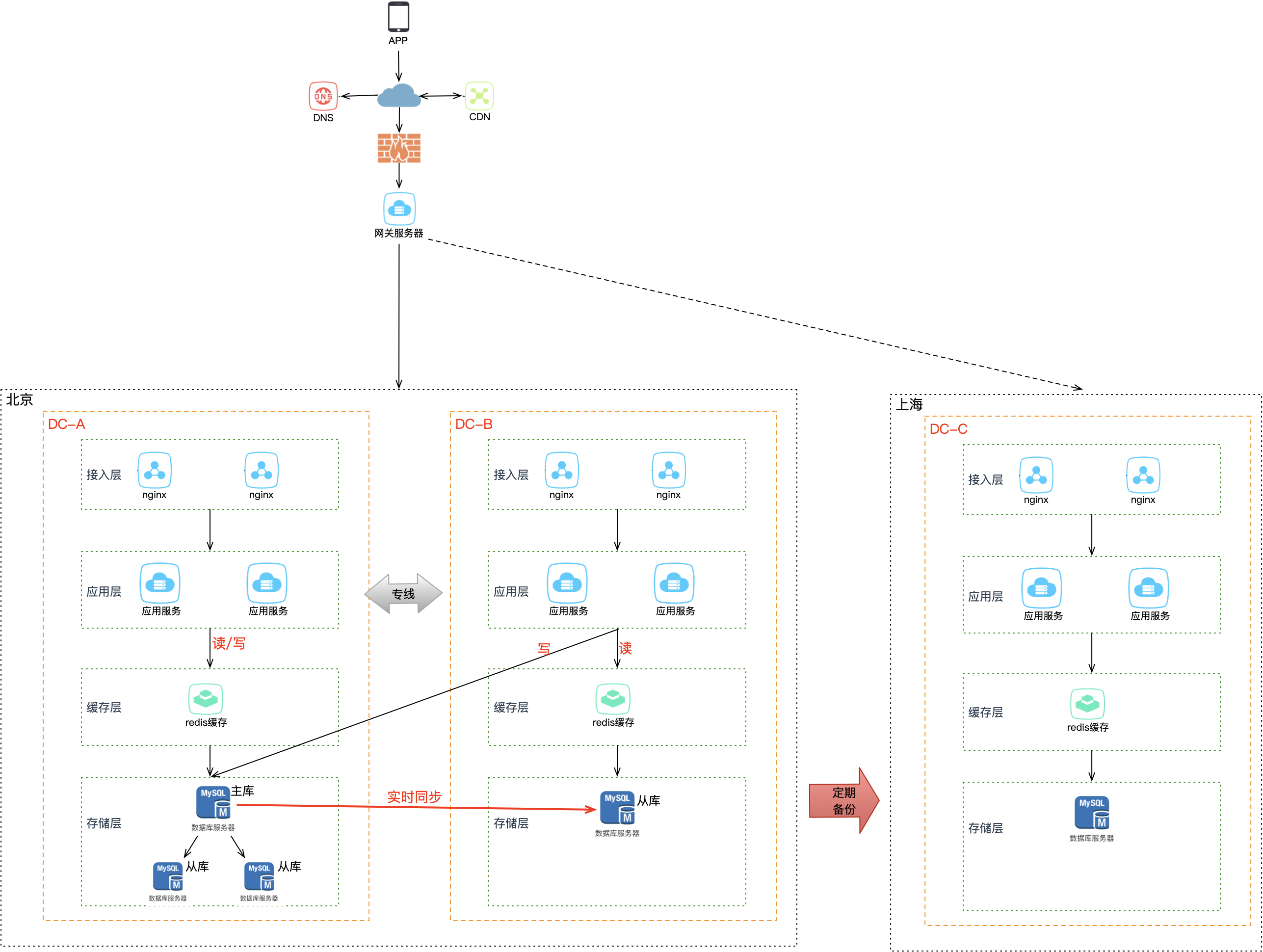
两地是指 2 个城市,三中心是指 3 个机房,其中 2 个机房在同一城市同时提供服务(同城双活),第 3 个机房部署在异地只做数据灾备。这种架构方案常用于银行、金融、政企项目。但问题依旧:启用灾备机房需要时间,且启用后的服务不确定能否如期工作。
一句话总结:部署架构的演进就是不断用冗余换可用性的过程——从数据冗余到机房冗余,从同城冗余到异地冗余,每一步都在更大维度上做备份。
异地双活:跨越延迟的鸿沟
为什么"简单异地部署"行不通?
如果把同城双活的架构直接搬到异地(例如 A 在北京、B 在上海),会遇到一个致命问题——网络延迟。
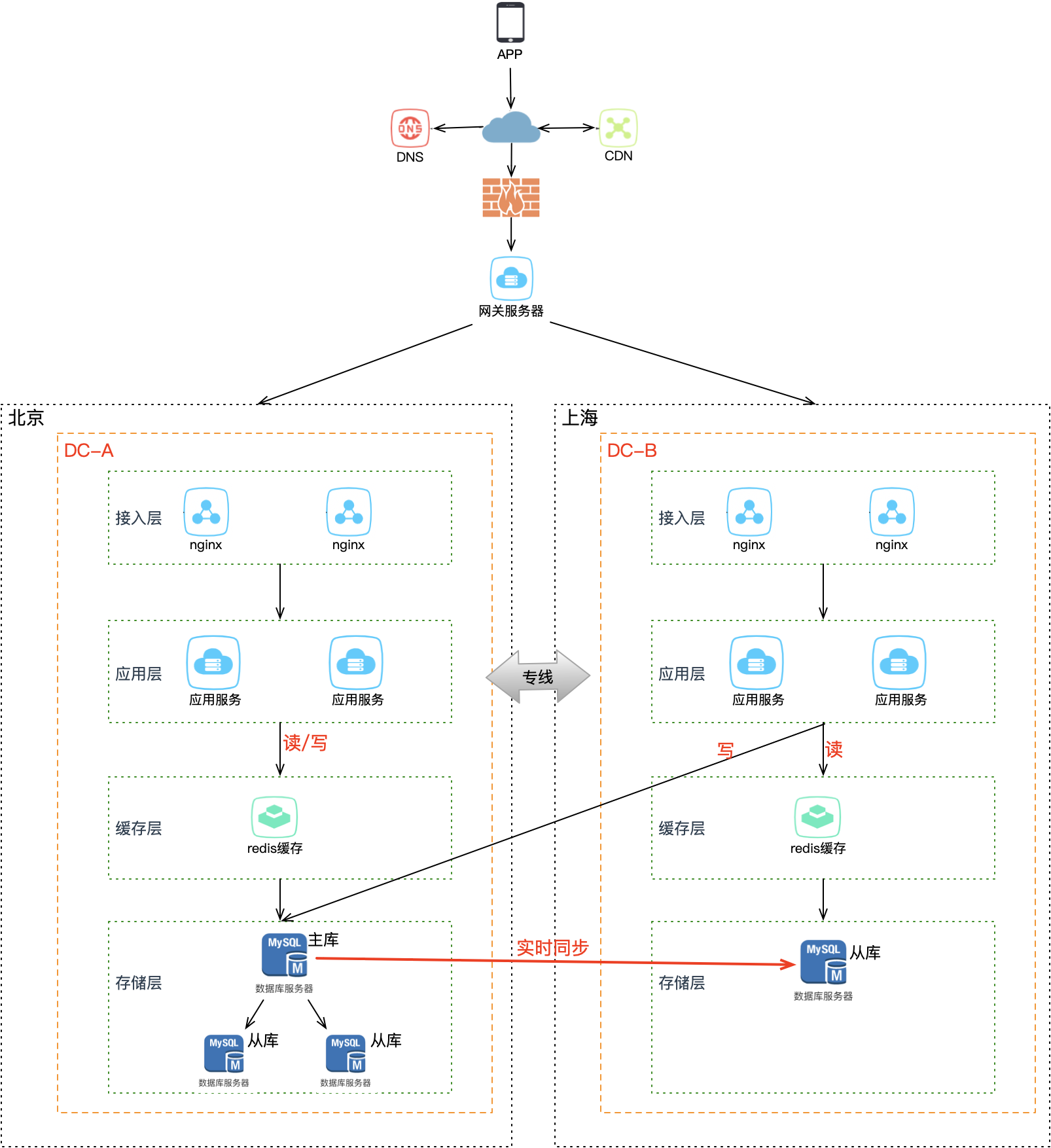
北京到上海约 1300 公里,即使光纤以光速传输,一个来回也需要近 10ms。加上路由器、交换机等设备,实际延迟可达 30ms 左右。不止是延迟,远距离专线的质量远不如机房内网——延迟波动、丢包、甚至中断都是常态,不能过度信任和依赖跨城专线。
对业务的影响体现在:在 App 打开一个页面可能会访问后端几十个 API,如果每次都跨机房访问,整个页面的响应延迟可能达到秒级——这是不可接受的。
虽然机房按同城双活的模型部署在了异地,但这本质上是一种伪异地双活。
真正的异地双活:机房内闭环
既然跨机房延迟是客观存在的物理限制,核心思路就是尽量避免跨机房调用——每个机房的请求在本机房内完成闭环。上海机房的应用不能再跨机房去读写北京机房的存储,只允许读写上海本地的存储。
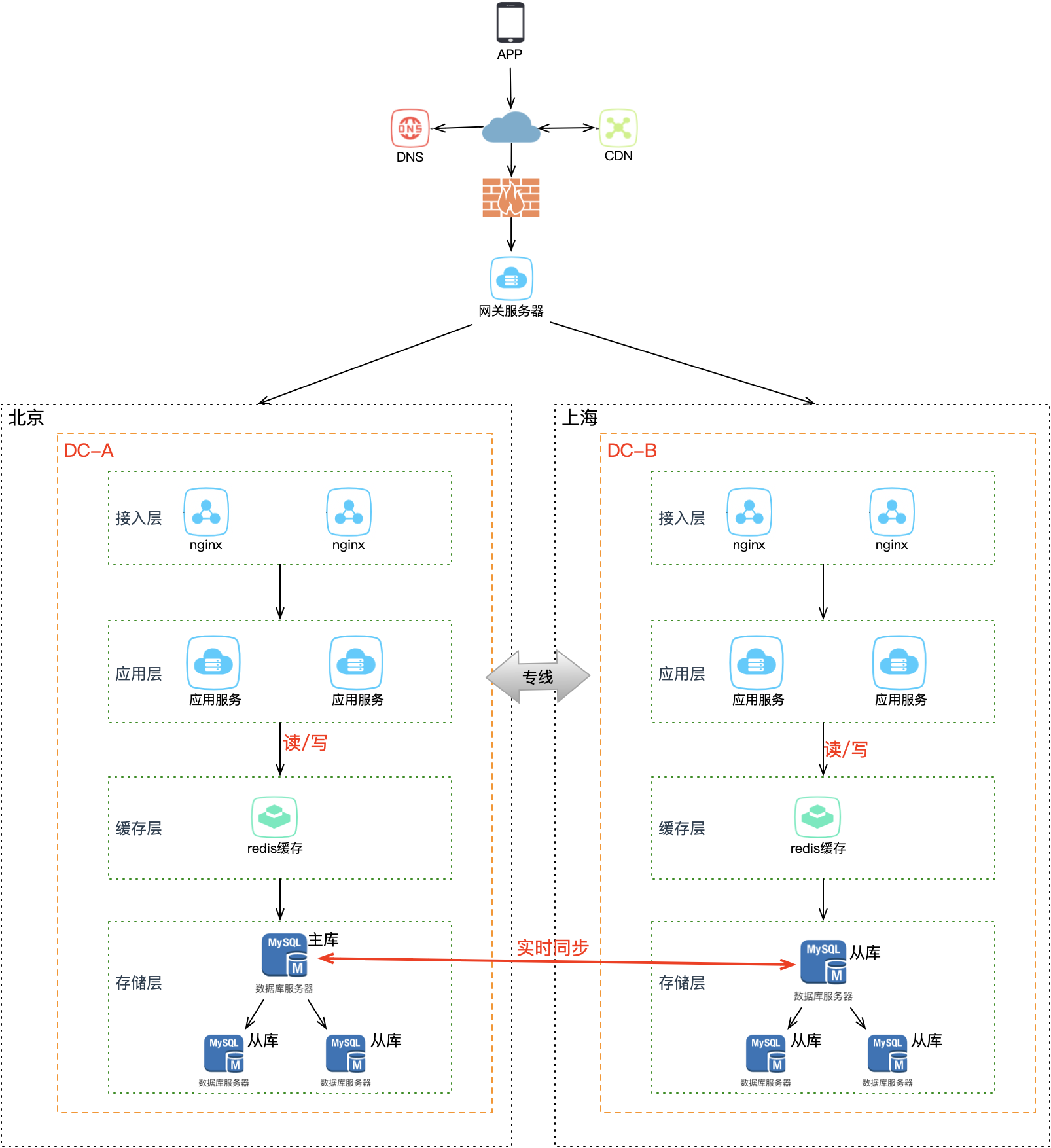
这意味着上海机房的存储不能再是北京机房的从库,而是也要变为主库。没错,两个机房的数据库必须都是主库,而且数据还要互相同步:
| 改造项 | 说明 |
|---|---|
| 数据库双主 | 两个机房的数据库都是主库,支持本地读写 |
| 双向数据同步 | 任一机房写入的数据,自动同步到另一个机房 |
| 全量数据 | 两个机房都拥有全量数据,支持任意切换 |
数据双向同步
怎么实现这种双主架构?MySQL 本身就提供了双主架构,支持双向复制。但 Redis 等数据库并没有提供这个功能,所以必须开发对应的数据同步中间件来实现双向同步。除了数据库之外,项目里用到的消息队列(Kafka、RocketMQ 等)也是有状态服务,同样需要开发双向同步的中间件。
有了数据同步中间件就能达到这样的效果:北京机房写入 order=AAAAA,上海机房写入 order=BBBBB,数据通过中间件双向同步,最终两个机房都拥有两条数据。使用中间件同步数据可以容忍专线的不稳定——专线出问题时中间件自动重试直到成功,达到数据最终一致性。
数据冲突问题
两个机房都可写,操作的不是同一条数据还好,如果修改的是同一条数据就会发生冲突。用户短时间内发起两个修改请求,都是修改同一条数据:一个请求落在北京机房修改了 order=AAAAA(还未同步到上海),另一个请求落在上海机房修改了 order=BBBBB(还未同步到北京),两个机房以谁为准?
系统发生故障并不可怕,可怕的是数据发生错误,因为修正数据的成本太高了,这都是血淋淋的教训。
解决数据冲突:路由分片
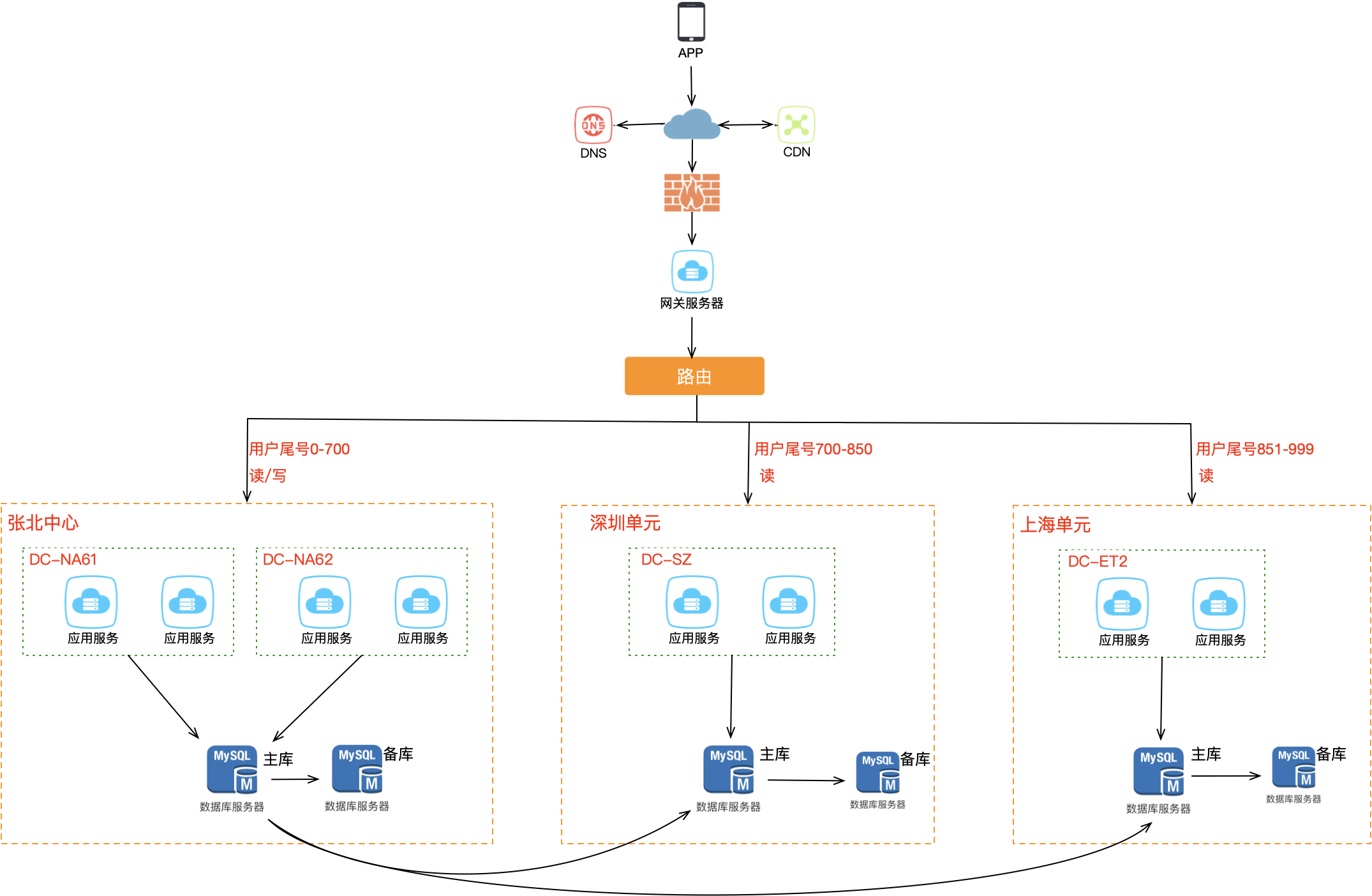
核心思想是:在最上层接入流量时就把用户区分开,部分用户固定打到北京机房,其他用户固定打到上海机房,进入某个机房后所有业务操作都在该机房内完成,从根源上避免冲突。所以需要在接入层之上部署路由层,根据规则将用户分流到不同机房。
常见的分片策略有两种:
策略一:哈希分片
最上层的路由层根据用户 userId 计算哈希值取模,从路由表中找到对应机房。例如一共 1000 个用户,用户 0700 路由到北京机房,701999 路由到上海机房,这样就避免了同一个用户修改同一条数据的情况发生。
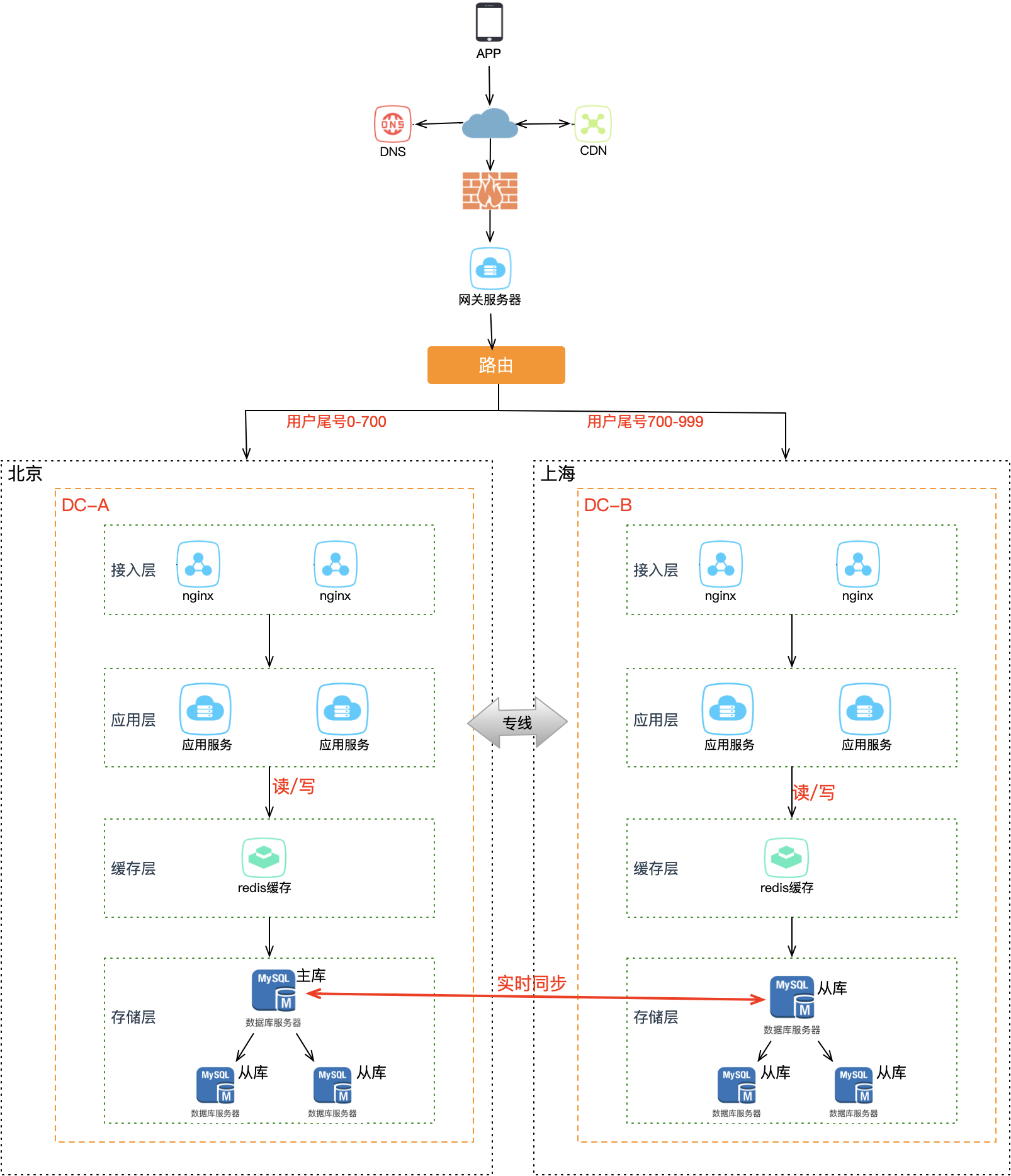
对于未登录用户的处理:方案 A 是全部路由到固定机房;方案 B 是根据设备 ID 进行哈希取模路由。
策略二:地理位置分片
非常适合与地理位置密切相关的业务(打车、外卖等)。拿外卖服务举例,商家、用户、骑手都在相同的地理范围内,天然适合按地域分片。例如北京、河北、内蒙古地区的请求打到北京机房,上海、浙江、江苏地区的请求打到上海机房。
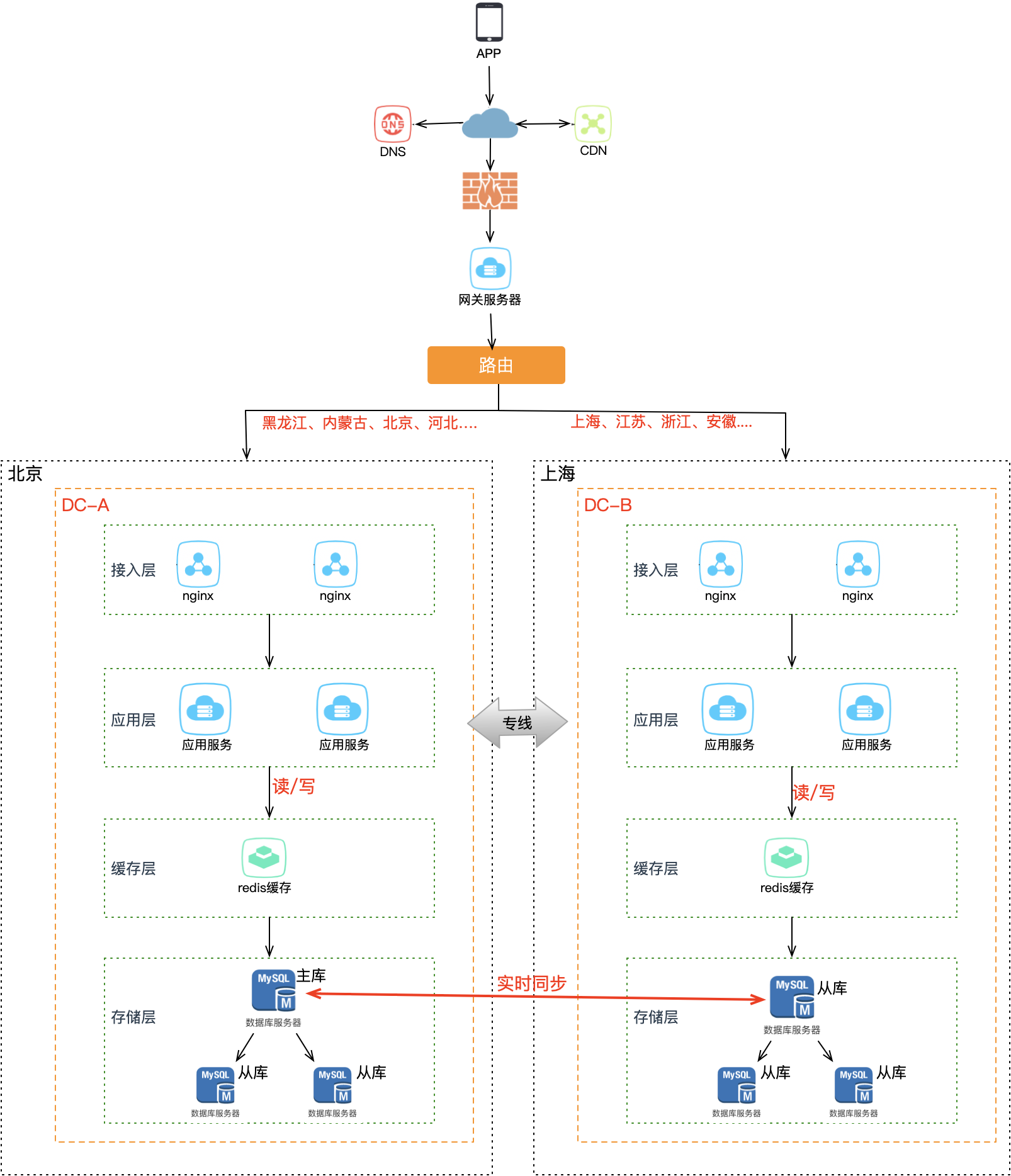
总之分片的核心思想在于:同一个用户的相关请求只在一个机房内完成所有业务闭环,不再出现跨机房访问——在阿里内部这叫做单元化。现在两个机房都可以接收读写流量,底层存储保持双向同步,两个机房都拥有全量数据,任意机房故障时另一个可接管全部流量。进一步想,因为机房部署在异地,还可以更细化地优化路由规则,让用户访问就近的机房,系统性能也会大大提升。
全局数据的特殊处理
有一类数据无法做分片——全局强一致数据,典型如商品库存。这类数据只能采用"写主机房、读从机房"的方案,无法真正双活。
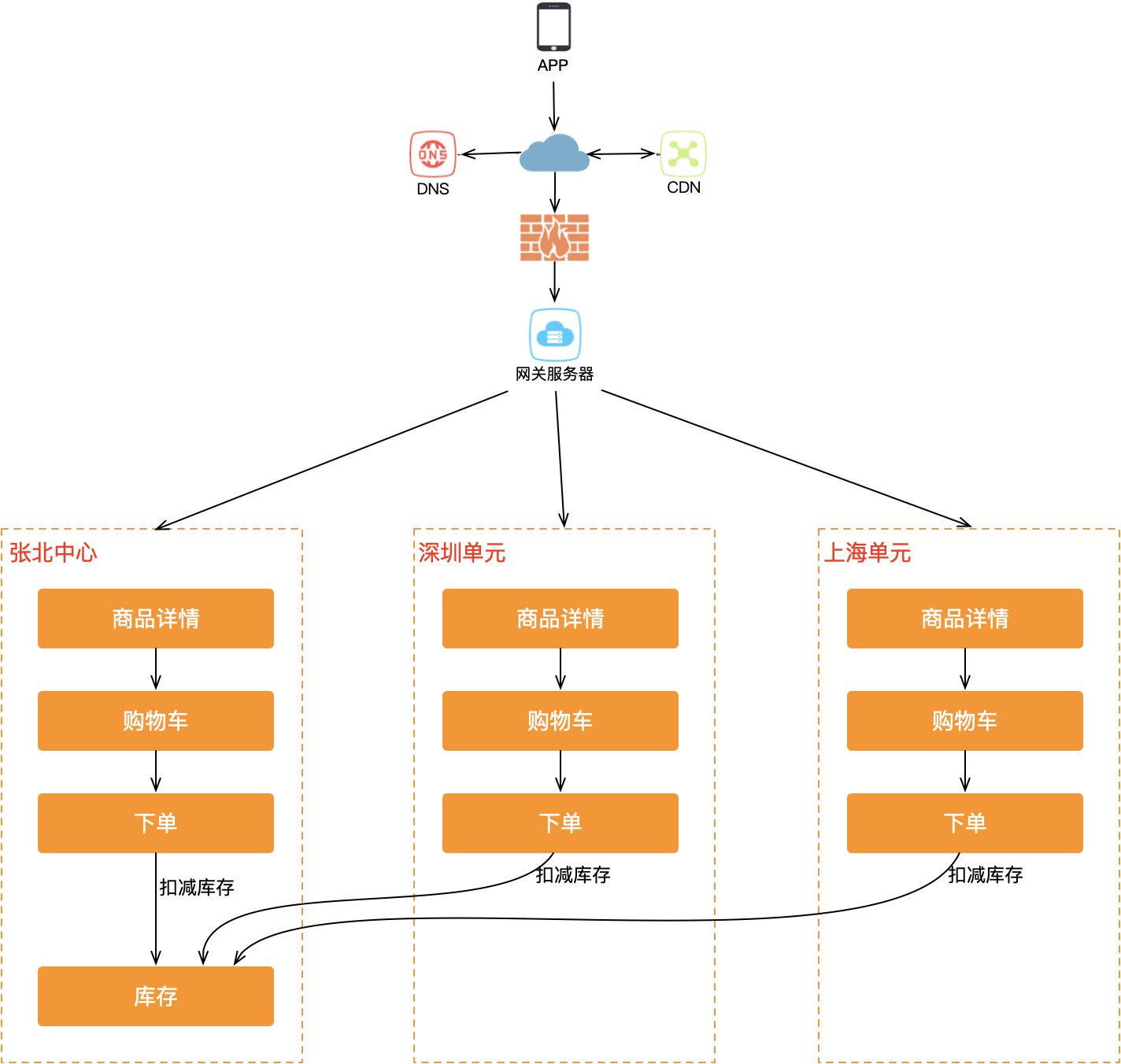
这意味着在交易链路中,虽然全链路都做了机房内闭环,到了库存扣减这一步又回到了中心机房,单元化闭环被打破了。至少从技术层面,库存扣减这个问题很难解决。但如果从业务角度思考呢?
一种解决思路是库存分摊:将一个商品的库存拆分到不同机房,每个机房独立扣减本地库存,再通过库存调拨程序在机房间进行库存共享和再平衡。
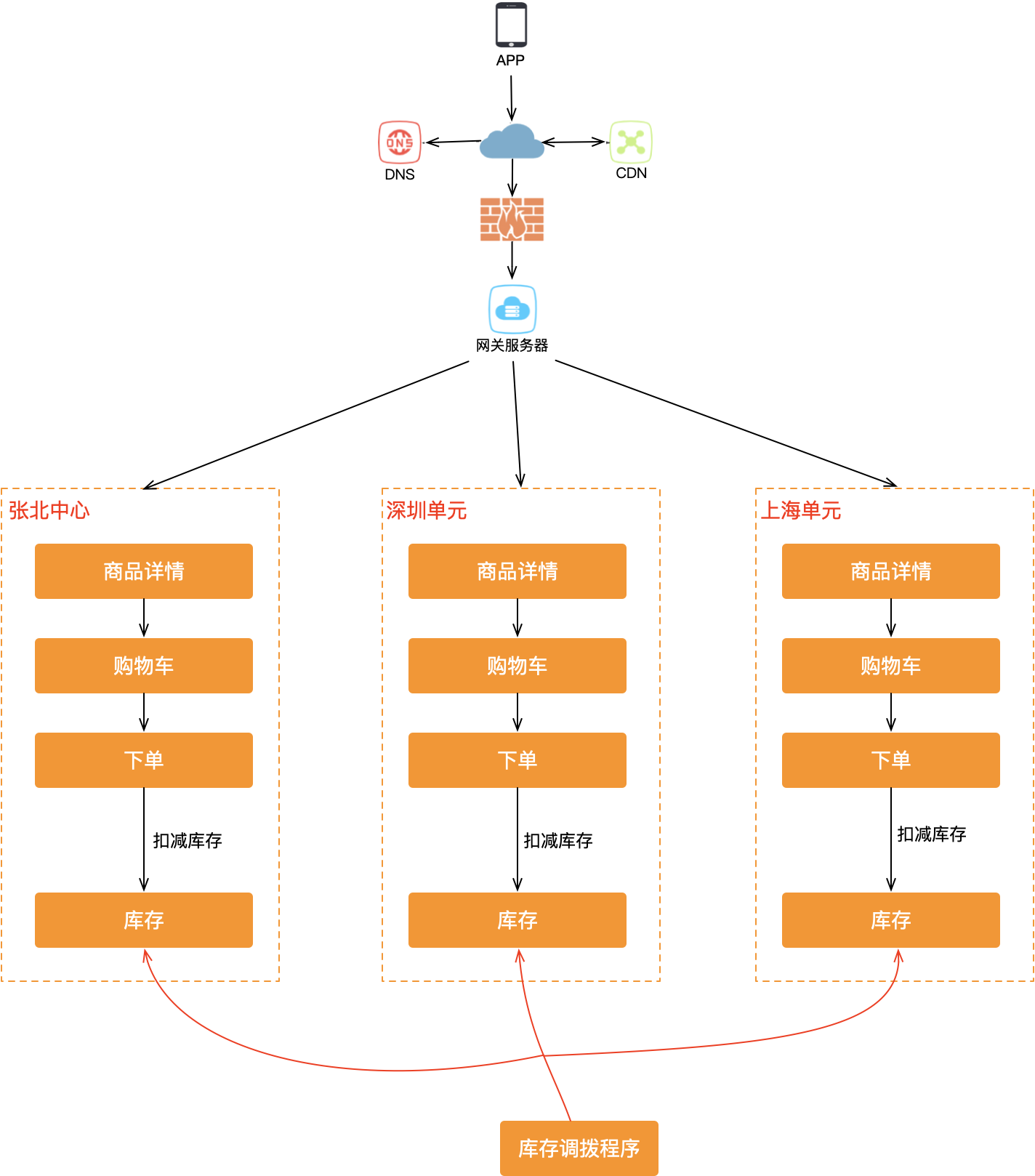
| 场景 | 方案 |
|---|---|
| 普通交易 | 库存分摊 + 库存调拨程序保证机房间库存共享 |
| 秒杀场景 | 各机房独立扣减,无需调拨(库存本就要被快速消耗完) |
路由规则、路由转发、数据同步中间件、数据校验兜底策略,不仅需要强大的中间件支撑,同时还要业务配合改造等一系列工作,没有足够的人力物力这套架构很难落地实施。
一句话总结:异地双活的核心是"机房内闭环"——通过路由分片让每个用户的请求在单个机房内完成所有业务操作,从根源上规避跨城延迟和数据冲突。
异地多活:从双活到 N 活
按照单元化的方式,每个机房可以部署在任意地区,随时扩展新机房,只需在最上层定义好分片规则。但随着机房数量增多,数据同步的复杂度急剧上升——每个机房写入数据后需要同步到所有其他机房,网状拓扑的复杂度为 O(N²)。
从网状到星状
业界的优化方案是将网状架构升级为星状:确立一个中心机房,所有数据同步都以中心机房为枢纽。
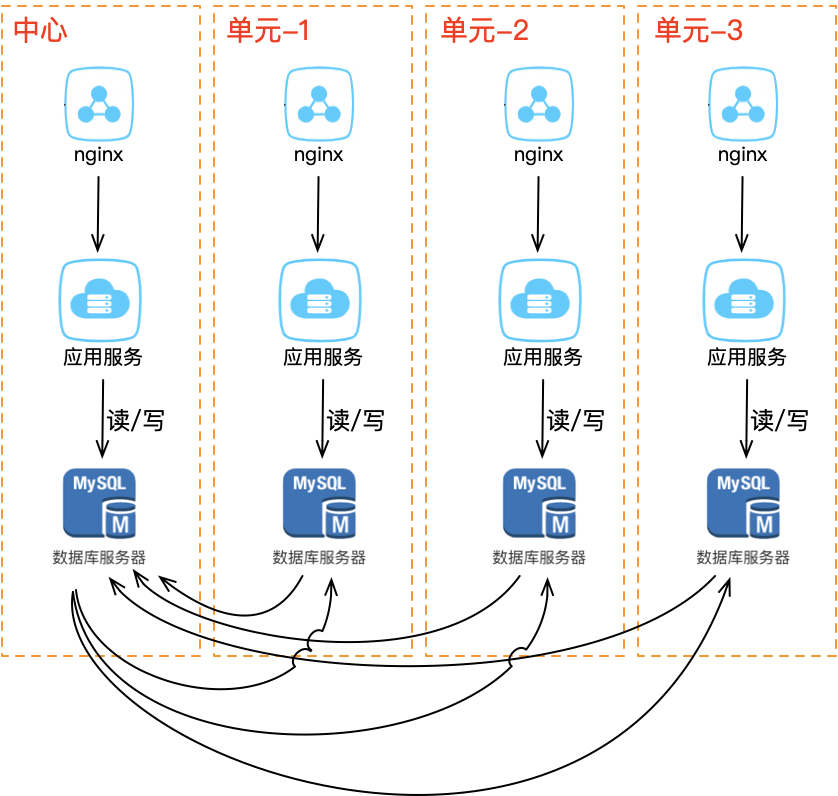
| 对比项 | 网状同步 | 星状同步 |
|---|---|---|
| 同步复杂度 | O(N²),每增一个机房所有机房都需改造 | O(N),只需同步到中心机房 |
| 扩展性 | 差 | 好,新机房只需和中心建立同步关系 |
| 中心依赖 | 无 | 中心机房稳定性要求高 |
| 容灾 | 任一机房可接管 | 中心故障时可提升任一机房为新中心 |
星状架构的好处在于:一个机房写入数据只需同步到中心机房,中心再同步至其他机房;不需要关心一共部署了多少机房,扩展新机房的成本极低;中心机房故障时,可将任一单元机房提升为新中心,继续服务。
至此,系统真正实现了异地多活——多个机房同时对外提供服务,任意机房故障可快速切换,系统具备极强的扩展能力。
一句话总结:星状同步将数据同步复杂度从 O(N²) 降到 O(N),让多机房扩展真正变得可行。
阿里单元化实践
阿里在实施单元化时,根据业务特点采用了两种模式:交易单元化和导购单元化。为什么分这两种?核心原因是两者的流量模型不同,导致了不同的物理部署方案。
交易单元化 vs 导购单元化
| 对比维度 | 交易单元化 | 导购单元化 |
|---|---|---|
| 入口流量 | 入口清晰(商品详情→购物车→下单→支付) | 入口分散,大促时增加各种场景和玩法 |
| 链路特征 | 以写为主 | 大部分是读,系统间调用错综复杂 |
| 数据库模式 | WRITE 模式(本地读写,双向同步) | COPY 模式(中心写入,单元只读) |
| 单元化范围 | 全链路必须做单元化(对用户下单有直接影响) | 仅 C 端服务做单元化,商家后台中心化部署 |
| 资源成本 | 较高(每个单元完整部署) | 较低(商家后台等只部署在中心) |
交易链路的服务正常情况下都必须做单元化,因为对用户下单有实际影响。从商品详情到购物车、下单、支付这条链路以及涉及的相关服务都需要做单元化。
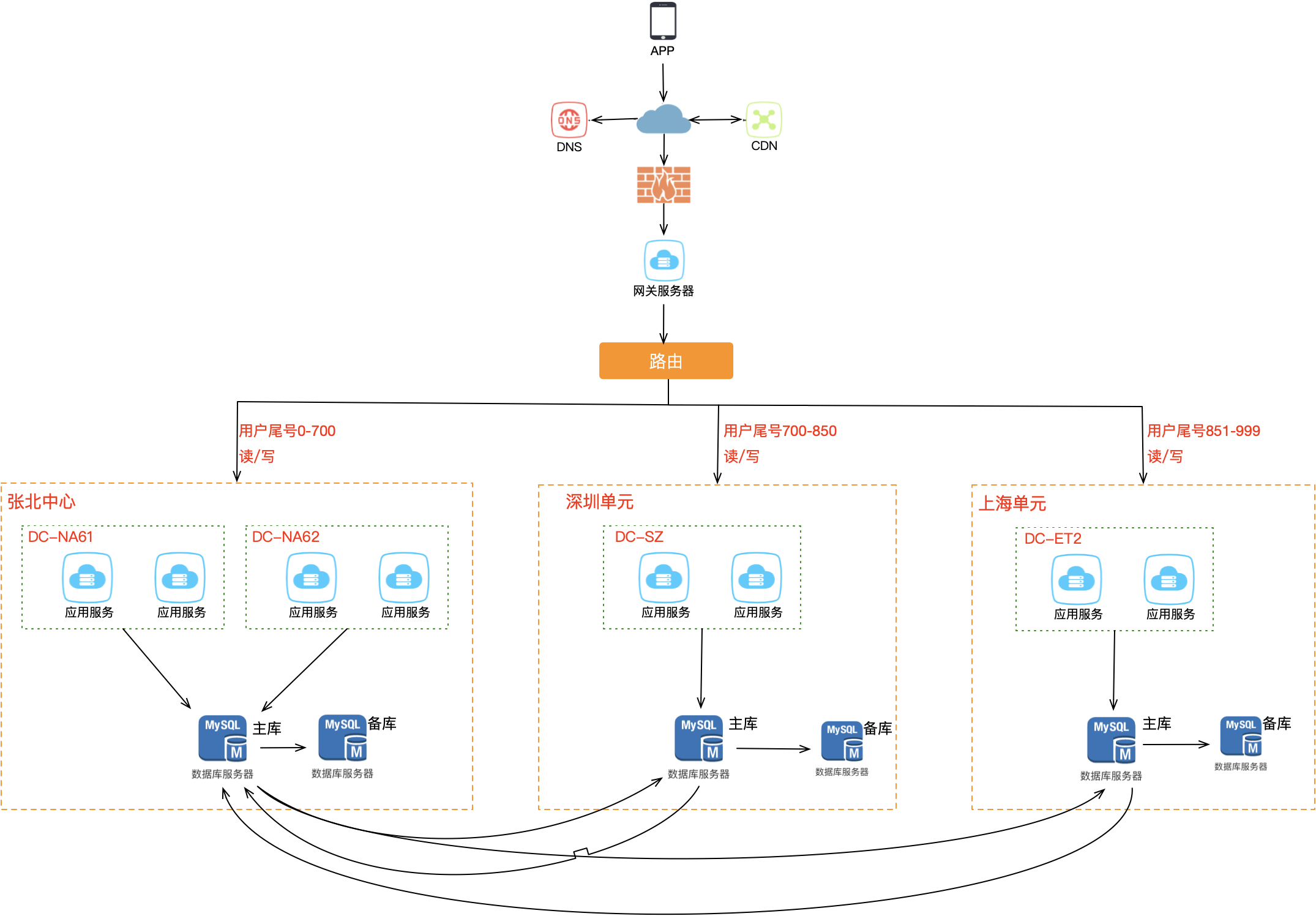
导购单元化相对特殊一些,例如一些商家后台服务没有必要做单元化,只需中心化部署即可,对于涉及 C 端的服务进行单元化部署即可。所以数据库部署采用 COPY 模式,这一点和交易链路采用 WRITE 模式不同。为什么这样做?对于商家后台来讲,可用性要求相对较低,影响商家操作可以等故障恢复后继续操作,对大盘交易影响不大。而且中心化部署能大幅节省资源成本和维护成本,也能降低开发人员的开发成本。
单元化路由透传
单元化的核心在于路由信息的全链路透传——从接入层到最底层的数据层,每一层都需要能够正确识别和传递路由参数:
| 层次 | 路由机制 |
|---|---|
| 接入层 | 浏览器发起请求时携带路由参数(cookie/header/body),接入层解析后路由到正确的应用 SLB,同时应用服务器仍然能从请求中拿到原生的路由参数 |
| 应用层 | 中间件从 HTTP 请求中提取路由参数保存到上下文,下一步应用可能会发起 RPC 调用或异步消息,因此路由参数还需要在 RPC 与消息层面透传 |
| RPC 层 | RPC 客户端从上下文取出路由参数,随 RPC 请求传递到远程 Provider;Provider 客户端识别出 Request 中的路由参数,也保存到调用上下文 |
| 消息层 | MQ 客户端发送消息时从当前上下文获取路由参数添加到消息属性;消费消息时从消息属性中取出路由参数,保存到调用上下文 |
| 数据层 | 数据脏写会造成很严重的后果,必须保证数据落库到正确单元的 DB |
单元协同与单元保护
在单元化演进过程中,有两个关键问题需要解决:
单元协同:某些特定业务场景需要保证数据强一致性(如库存扣减),这类服务只能在中心单元提供服务。所有对中心服务的调用都会直接路由到中心单元完成。
单元保护:系统自上而下各层都要具备纠错保护能力,保证业务按单元化规则正确流转:
| 保护层 | 纠错机制 |
|---|---|
| 接入层纠偏 | 流量进入接入层后,通过路由参数判断归属单元,非本单元流量代理到正确的目标单元,保证入口流量的正确性 |
| RPC 纠偏 | RPC Consumer 端根据请求的单元信息进行路由选址,对错误的流量服务调用会计算出正确的目标单元,跨单元调用目标单元服务,保证服务流转逻辑的一致性 |
| 数据层保护 | 数据库层面的最后防线,防止数据写入错误的单元 |
一句话总结:阿里单元化的精髓在于"分而治之"——交易链路用 WRITE 模式保证机房闭环,导购链路用 COPY 模式节省成本,全链路路由透传确保请求在正确的单元内流转。
总结
异地多活的演进,本质上是一部用冗余换可用性的发展史。整个架构演进可以浓缩为以下全景:
| 阶段 | 方案 | 机房数 | 可用性 | 核心特点 | 主要局限 |
|---|---|---|---|---|---|
| 1 | 单机架构 | 1 | < 99% | 最简单 | 单点故障,数据丢失 |
| 2 | 主从副本 | 1 | ~99.9% | 数据冗余 | 机房级故障无法应对 |
| 3 | 同城灾备 | 2(同城) | ~99.95% | 机房级冗余 | 备用机房未经验证 |
| 4 | 同城双活 | 2(同城) | ~99.99% | 双机房实时服务 | 无法应对城市级灾难 |
| 5 | 两地三中心 | 3(两城) | ~99.99% | 异地数据备份 | 灾备机房启用慢 |
| 6 | 异地双活 | 2(异地) | ~99.99%+ | 机房内闭环,双主同步 | 需要大量中间件和业务改造 |
| 7 | 异地多活 | N(多地) | ~99.999% | 星状同步,任意扩展 | 实施复杂度高,需要强大的基础设施支撑 |
要想真正实现异地多活落地,还需要遵循一些原则:业务梳理、业务分级、数据分类、数据最终一致性保障、机房切换一致性保障、异常处理等等,同时相关的运维设施、监控体系也要能跟得上。并不是所有业务都需要做多活,需要根据业务重要程度分级——核心交易链路做完整单元化,非核心业务中心化部署节省成本。路由规则、路由转发、数据同步中间件、数据校验兜底策略,没有足够的人力物力这套架构很难落地实施。
好的架构不是一步到位的,而是随着业务体量的增长逐步演进的。理解每一步演进背后的驱动力和技术挑战,比直接套用某个方案更加重要。